 R语言总和性试验Word下载.docx
R语言总和性试验Word下载.docx
- 文档编号:16540007
- 上传时间:2022-11-24
- 格式:DOCX
- 页数:29
- 大小:283.23KB
R语言总和性试验Word下载.docx
《R语言总和性试验Word下载.docx》由会员分享,可在线阅读,更多相关《R语言总和性试验Word下载.docx(29页珍藏版)》请在冰豆网上搜索。
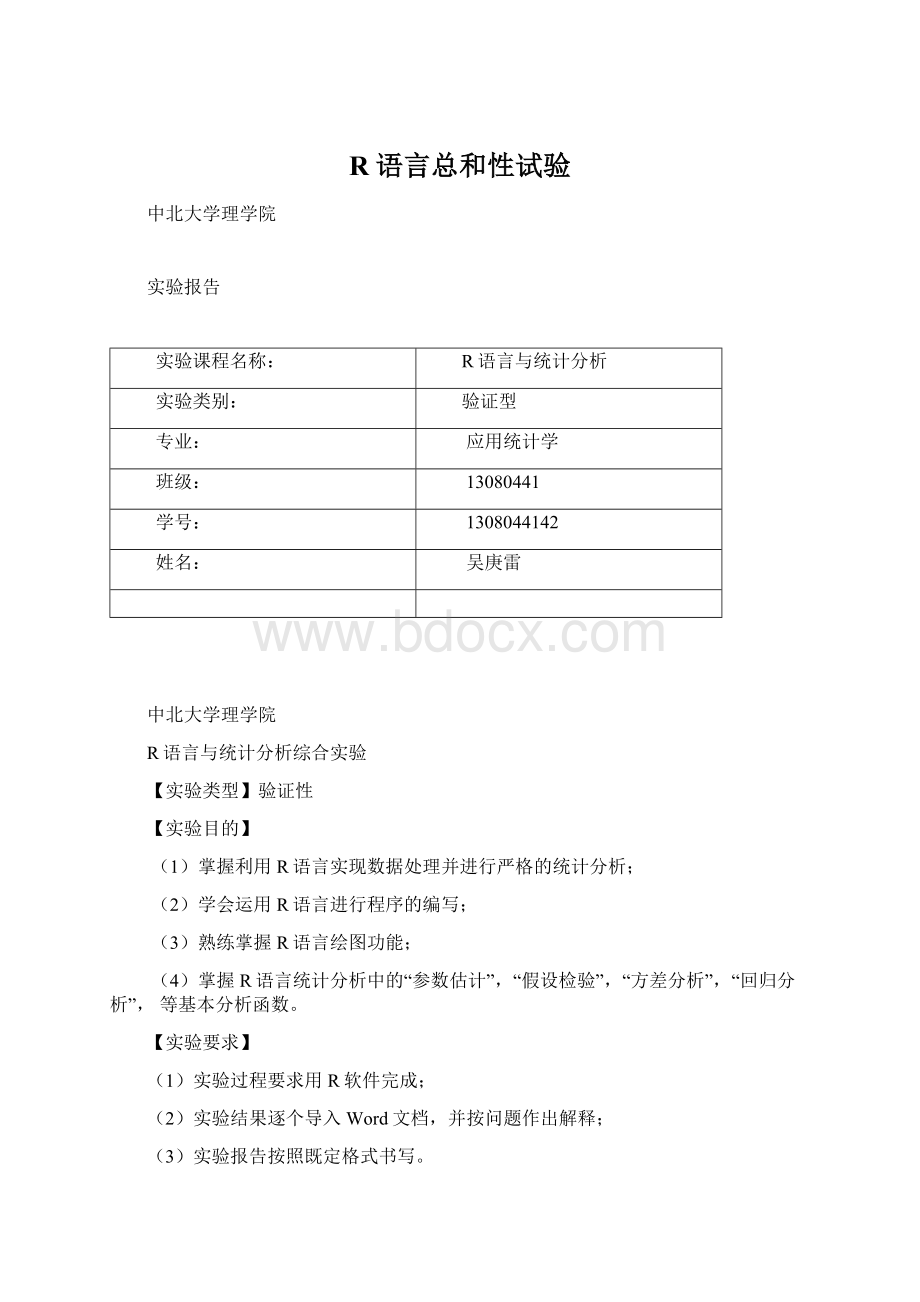
x<
-rep(c(3,2,1),c(3,4,5))
2、
由1.2...16构成两个方阵,其中矩阵A按列输入,矩阵B按行输入,并计算以下:
A<
-matrix(1:
16,4,4)
B<
16,4,4,byrow=TRUE)
C=A+B
>
D=A*B
3、
E=A%*%B
4、
F<
-A[-3,]
[,1][,2][,3][,4]
[1,]15913
[2,]261014
[3,]481216
G<
-B[,-3]
[,1][,2][,3]
[1,]124
[2,]568
[3,]91012
[4,]131416
H=F%*%G
函数solve()有两个作用;
solve(A,b)可用于求解线性方程组Ax=b,solve(A)可用于求解矩阵A的逆,用两种方法编程求解方程组Ax=b的解。
9,3,3,byrow=TRUE)
A[3,3]=10
b=matrix(1:
1,3,1)
solve(A,b)
[,1]
[1,]-1.000000e+00
[2,]1.000000e+00
[3,]3.806634e-16
用三种方法求解它们的內积与外积。
x=c(1,2,3,4,5)
y=c(2,4,6,8,10)
a=t(x)%*%y
e=x%*%t(y)
b=crossprod(x,y)
>
f=outer(x,y)
c=x%*%y
d=x%o%y
5、
编写一个用二分法求解非线性方程的根的函数,并求方程x^3-x-1=0在区间[1,2]内的根,精度要求e=10^-5.
程序:
fzero<
-function(f,a,b,eps=1e-5)
{
if(f(a)*f(b)>
0)list(fail="
findingrootisfail!
"
)
else{repeat{if(abs(b-a)<
eps)
break
-(a+b)/2
if(f(a)*f(x)<
0)
b<
-x
elsea<
-x}
list(root=(a+b)/2,fun=f(x))}}
f<
-function(x)x^3-x-1
fzero(f,1,2,1e-5)
$root
[1]1.324718
$fun
[1]-1.405875e-05
第三章:
从1到100个自然数中随机不放回的抽取5个数,并求它们的和。
sum(sample(1:
100,5))
[1]205
从一副扑克牌(52张)中随机抽取5张求以下概率
抽到的是10,J,Q,K,A;
(1)>
4/choose(52,5)
[1]1.539077e-06
抽到的是同花顺
(2)9*choose(4,1)/choose(52,5)
[1]1.385169e-05
从正态分布N(100,100)中随机产生1000个随机数,
(1)rnorm(1000,mean=100,sd=10)
结果随机执行//产生1000个随机数
作出这1000个正态随机数的直方图;
hist(rnorm(1000,mean=100,sd=10))
结果随机执行//产生对应直方图
从这1000个随机数中随机有放回的抽取500个作出直方图
(2)>
A<
-rnorm(1000,mean=100,sd=10)
sample(A,500,replace=TRUE)
或者sample(rnorm(1000,mean=100,sd=10),500)
结果随机执行//产生500个对应随机数
hist(sample(A,500,replace=TRUE))
比较它们的样本均值和样本方差
(3)>
mean(rnorm(1000,mean=100,sd=10))
[1]100.0266
var(rnorm(1000,mean=100,sd=10))
[1]98.5499
mean(sample(rnorm(1000,mean=100,sd=10),500))
[1]99.9142
var(sample(rnorm(1000,mean=100,sd=10),500))
[1]106.2611
模拟随机游动:
从标准正态分布中产生1000个随机数,并用函数cumsum()作出累积和,最后使用命令plot()作出随机游动示意图
rnorm(1000,mean=0,sd=1)
//产生1000个标准正态分布随机数
cumsum(rnorm(1000,mean=0,sd=1))
//累积和
plot(cumsum(rnorm(1000,mean=0,sd=1)))
//随机执行产生随机游动图
从标准正态分布中随机产生100个随机数,由此数据求总体均值的95%的置信区间
t.test(rnorm(100,mean=0,sd=1))
//t.test(c(数据))专用于求出95%的置信区间
结果如下:
OneSamplet-test
data:
rnorm(100,mean=0,sd=1)
t=0.31167,df=99,p-value=0.7559
alternativehypothesis:
truemeanisnotequalto0
95percentconfidenceinterval:
-0.16384600.2249099
sampleestimates:
meanofx
0.03053192
第四章:
1、模拟得到1000个参数为0.3的伯努利分布随机数,并用图示表示出来
plot(rbinom(1000,1,0.3))
用命令rnorm()命令产生1000个均值为10,方差为4的正态分布随机数,用直方图呈现数据分布并添加核密度曲线;
x=rnorm(1000,mean=10,sd=2)%生成正态分布随机数
hist(x,xlim=c(min(x),max(x)),probability=T,nclass=max(x)-min(x)+1,col='
lightblue'
main='
Normaldistribution,mean=10,sd=2'
)%绘制直方图
lines(density(x,bw=1),col='
red'
lwd=3)%添加核密度曲线
7、
假定某校100名女生的血清总蛋白含量服从均值为75,标准差为3的分布,并假定数据由下面命令产生:
options(digits=4)
x=rnorm(100,75,3)%生成随机数
计算样本均值,标准差,以及五数概括;
summary(x)%计算均值和五数
Min.1stQu.MedianMean3rdQu.Max.
65.772.474.274.776.782.3
sd(x)%标准差
[1]3.338
绘制出直方图,核密度估计曲线,和QQ图;
lightgreen'
Normaldistrubution,mean=75,sd=3'
lines(density(x,bw=1),col='
qqnorm(x,main="
NormalityCheckviaQQPlot"
qqline(x,col='
)%绘制QQ图
根据数据绘制出茎叶图和框须图;
stem(x)%绘制茎叶图
Thedecimalpointisatthe|
68|344
70|16889937
72|0112233667902334556777789
74|0012244556688990023588
76|001223667779011234459
78|000255790158
80|2378906
82|20
boxplot(x)%绘制框须图
8、
某校测得20名学生的4项指标:
性别,年龄,身高,体重,具体数据如课本表4.1所示:
(1)、绘制体重对身高的散点图;
mydata<
-read.delim("
clipboard"
plot(mydata$height~mydata$weight,xlab="
Weight"
ylab="
height"
lines(lowess(mydata$height,mydata$weight),lwd=2)
(2)、绘制不同性别下体重对身高的散点图;
coplot(mydata$height~mydata$weight|mydata$性别,xlab="
weight"
height"
(3)、绘制不同年龄段体重对身高的散点图;
coplot(mydata$height~mydata$weight|mydata$年龄,xlab="
(4)、绘制不同性别下不同年龄段体重对身高的散点图;
coplot(mydata$height~mydata$weight|mydata$性别*mydata$年龄,xlab="
weight"
第五章:
设总体X是用无线电测距仪测量距离的误差,它服从(A,B)上的均匀分布在200次测量中,误差Xi的次数有ni次:
求A,B的矩法估计值;
x<
-rep(c(3,5,7,9,11,13,15,17,19,21),c(21,16,15,26,22,14,21,22,18,25))%读入数据
a<
-2*mean(x)
-12*var(x)
z=b/a
-(a-z)/2%A的矩估计值
A=4.035345
B<
-(a-A)%B的矩估计值
B=20.58466
2、为检验某自来水消毒设备的效果,从消毒后的水中随机抽取50L,化验每L水中大肠杆菌的个数(假设其服从泊松分布),化验结果如表中所示,试问平均每升水中大肠杆菌的个数为多少时,才能使上述情况概率达到最大;
-rep(c(0,1,2,3,4,5,6),c(17,20,10,2,1,0,0))%读取数据
lambda<
-mean(x)%定义泊松分布的矩估计
lambda%输出矩估计值
[1]1
已知某种木材的横纹抗压力服从N(mu,sigma^2),现在对十个试件作横纹抗压力实验数据如下:
(1)、求mu的置信水平为0.95的置信区间
-c(482,493,457,471,510,446,435,418,394,469)%读取数据
t.test(x)%方差未知时求均值的置信区间,调用t.test函数
x
t=41.08,df=9,p-value=1.495e-11
432.3069482.6931
meanofx
457.5
置信区间为(432.3069,482.6931)
某卷烟厂生产两种卷烟A和B,现在分别对两种香烟的尼古丁含量进行六次测试,结果如下:
-c(25,28,23,26,29,22)
-c(28,23,30,35,21,27)
(1)、试问两种卷烟中的尼古丁含量的方差是否相等?
var.test(A,B)
Ftesttocomparetwovariances
AandB
F=0.3,numdf=5,denomdf=5,p-value=0.2
trueratioofvariancesisnotequalto1
0.041872.13821
ratioofvariances
0.2992
(2)、试求两种卷烟的尼古丁平均含量差的95%的置信区间;
two.sample.ci<
-function(x,y,conf.level=0.95,sigma1,sigma2){
options(digits=4)
m=length(x);
n=length(y)
xbar=mean(x)-mean(y)
alpha=1-conf.level
zstar=qnorm(1-alpha/2)*(sigma1/m+sigma2/n)^(1/2)
xbar+c(-zstar,+zstar)
}
y<
sigma1=sqrt(var(x))
sigma2=sqrt(var(y))
two.sample.ci(x,y,conf.level=0.95,sigma1,sigma2)
[1]-4.06020.3935
为比较俩个小麦品种的产量,选择22块条件相似的试验田,采用相同的耕作方法做试验,结果播种甲品种的12块试验田的单位面积产量和播种乙的12块试验田的单位面积产量如表所示,假定每个品种的单位面积产量均服从正太分布,甲品种产量方差为2140,乙品种产量方差为3250.试求这俩个品种平均面积产量差的置信水平为0.95的置信上限和置信水平为0.90的置信下限;
程序如下:
编写函数求产量差的直线区间
-c(628,583,510,554,612,523,530,615,573,603,334,564)
-c(535,433,398,470,567,480,498,560,503,426,338,547)
sigma1<
-2140
sigma2<
-3250
[1]31.29114.37
-function(x,y,conf.level=0.90,sigma1,sigma2){
two.sample.ci(x,y,conf.level=0.90,sigma1,sigma2)%调用函数进行双样本已知方差估计均值
[1]37.97107.69
因此置信水平为0.95的置信上限为:
114.37;
置信水平为0.90的置信下限为:
37.97
(6)、
有两台机床生产同一型号的滚珠根据以往经验得知,滚珠的直径都服从正态分布,现在从这两台机床生产的滚珠中随机抽取7个和9个,测得其直径的数据如下:
试问机床乙生产的滚珠的方差是否比甲的方差小?
-c(15.2,14.5,15.5,14.8,15.1,15.6,14.7)
-c(15.2,15.0,14.8,15.2,15.0,14.9,15.1,14.8,15.3)
var.test(x,y)%调用函数进行双样本方差比估计
xandy
F=5.2,numdf=6,denomdf=8,p-value=0.04
1.12129.208
5.216
(7)、
某公司对本公司生产的两种自行车型号A,B的销售情况进行调查,随机选取400人询问他们对A,B的选择,其中有224人喜欢A,试求顾客中喜欢A的人数比例p的置信水平为99%的区间估计;
prop.test(224,400,correct=TRUE)%调用函数进行单总体比率p的区间估计
1-sampleproportionstestwithcontinuitycorrection
224outof400,nullprobability0.5
X-squared=5.5,df=1,p-value=0.02
truepisnotequalto0.5
0.50980.6091
p
0.56
所以我们以0.95的置信水平认为比例p落在(0.5098,0.6091)中,点估计为0.56
(8)、
某公司生产一批新产品,产品总体服从正态分布,现要估计这批产品的平均重量,最大允许误差为1,样本标准差s=10,试问在95%的置信水平下至少要抽取多少个产品?
%定义函数
size.norm1<
-function(d,var,conf.level){
((qnorm(1-alpha/2)*var^(1/2))/d)^2
size.norm1(1,100,conf.level=0.95)%调用函数
[1]384.1
所以应该抽取384个产品
(9)、
size.bin<
-function(d,p,conf.level=0.95){
((qnorm(1-alpha/2))/d)^2*p*(1-p)
size.bin(0.01,0.05,0.90)%调用函数
[1]1285
需要抽取1285个样本
第六章:
(1)、
v<
-c(914,920,910,934,953,940,912,924,930)
t.test(v,mu=950)
v
t=-5,df=8,p-value=0.001
truemeanisnotequalto950
915.3937.3
926.3
由结果可知:
p值为0.001显著小于0.01,所以应该拒绝原假设,即:
认为这批枪弹的初速显著降低。
(3)、
下面给出了俩种的计算器充电以后所能使用的时间的观测值:
设俩样本独立且数据所属的俩个总体的密度函数至多差一个平移量,试问能否认为型号A的计算器平均使用时间比B长(0.01)?
-c(5.5,5.6,6.3,4.6,5.3,5.0,6.2,5.8,5.1,5.2,5.9)
-c(3.8,4.3,4.2,4.9,4.5,5.2,4.8,4.5,3.9,3.7,3.6,2.9)
t.test(x,y,var.equal=TRUE)
TwoSamplet-test
t=5.3,df=21,p-value=3e-05
truedifferenceinmeansisnotequalto0
0.79551.8212
meanofxmeanofy
5.5004.192
因为p值显著小于0.01,因此拒绝原假设,即:
(4)、
测得俩批电子器件的样本电阻
设这俩批器材的电阻值分别服从正态分布N和M,样本独立。
(1)试样本俩个总体的方差是否相等(0.01)?
(2)试样本


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 语言 总和 试验
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《雷雨》中的蘩漪人物形象分析 1.docx
《雷雨》中的蘩漪人物形象分析 1.docx
-
《经济法基础》第三章章节练习与答案解析.docx
-
安徽省合肥市包河区卫生健康系统招聘试题及答案解析.docx
-
《河中石兽》复习过程.docx
-
版二级建造师《公路工程管理与实务》考前检测 附答案.docx
-
保密安全制度监理组5篇修改版.docx
-
北师大版届九年级上学期期末考试英语试题I卷.docx
-
PACE产品及周期优化法系统结构复习课程.docx
-
常规变电站常规设计.docx
-
初三欧姆定律计算题题型整理.docx
-
《测绘管理与法律法规》模拟试题一附答案.docx
-
2测风工岗位练兵技术比武.docx
-
《小学语文不同课型的教学模式参考》1.docx
-
15高考宁夏英语及答案教学内容.docx
-
ABS圆形笔筒课程设计说明书.docx
-
c语言程序填空题.docx
-
茶艺师高级三级教学计划大纲.docx
-
场平土石方工程施工项目组织设计.docx
-
《人力资源管理》期末试题及答案教学内容.docx
-
《河南省高等学校教师实验人员中高级专业技术职务任职资格申报评审条件试行.docx
-
01钢结构制作施工工艺标准文档.docx
-
IIR数字滤波器的设计流程图.docx
-
005纺丝作业指导书.docx
-
1991高考化学试题.docx
-
GMP审核检查表与审核员指南.docx
-
成本会计试题二.docx
-
14001讲师心态调整培训讲座讲义体验版共14页文档.docx
-
cpld矩阵键盘.docx
-
《金融服务营销》.docx
-
NHR100过程校验仪140408.docx
-
Q+ Web 改版设计小结.docx
-
八年级上册古诗词鉴赏含参考答案.docx
-
《传播学原理》课程教学大纲.docx
-
中秋节祝福长辈短信.docx
-
最新MLA论文引用格式.docx
-
《公路水运工程安全生产监督管理办法》.docx
-
2FSK调制解调系统设计.docx
-
中小学易错多音字大全.docx
-
最新部编版三年级语文上册《古诗三首》教案.docx
-
《金刚》观后感范文.docx
-
种养殖专业合作社章程范本模板.docx
-
最新初中物理中考高频考点专题讲解《专题11机械功和机械能》附答案解析.docx
-
《老王》说课稿范文.docx
-
重力勘探重力的解释.docx
-
最新高考物理全真模拟试题附答案二精编版.docx
-
《美丽的小兴安岭》第二课时教案修改中语文.docx
-
最新会计工作岗位职责资料.docx
-
重阳节敬老院活动方案5篇.docx
-
《普通车床加工实训》课程标准.docx
-
最新精选高中教师校本研修个人计划.docx
-
注册会计师《审计》真题及答案.docx
