 intelNehalemEP处理器首发深度评测第二部分.docx
intelNehalemEP处理器首发深度评测第二部分.docx
- 文档编号:2150958
- 上传时间:2022-10-27
- 格式:DOCX
- 页数:35
- 大小:2.71MB
intelNehalemEP处理器首发深度评测第二部分.docx
《intelNehalemEP处理器首发深度评测第二部分.docx》由会员分享,可在线阅读,更多相关《intelNehalemEP处理器首发深度评测第二部分.docx(35页珍藏版)》请在冰豆网上搜索。
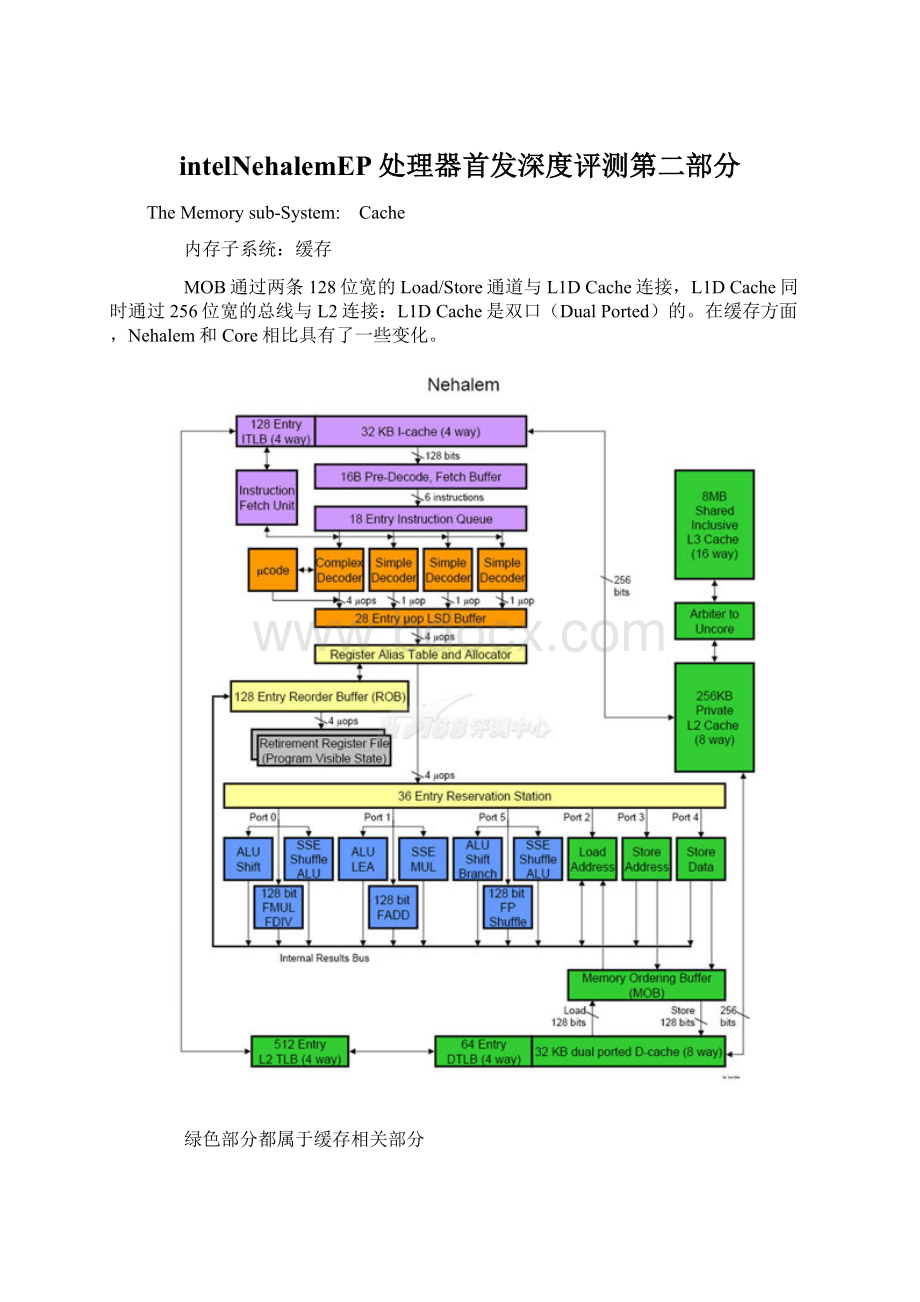
intelNehalemEP处理器首发深度评测第二部分
TheMemorysub-System:
Cache
内存子系统:
缓存
MOB通过两条128位宽的Load/Store通道与L1DCache连接,L1DCache同时通过256位宽的总线与L2连接:
L1DCache是双口(DualPorted)的。
在缓存方面,Nehalem和Core相比具有了一些变化。
绿色部分都属于缓存相关部分
Nehalem/Core的L1ICache(L1指令缓存)和L1DCache(L1数据缓存)都是32KB,不过Nehalem的L1ICache从以往的8路集合关联降低到了4路集合关联,L1DTLB也从以往的256条目降低到64条目(64个小页面TLB,32个大页面TLB),并且L1DTLB是在两个多线程之间动态共享的(L1ITLB的小页面部分则是静态分区,也就是64条目每线程,是Core2每线程128条目的一半;每个线程还具有7个大页面L1ITLB)。
NehalemTLB架构
为什么L1ICache的集合关联降低了呢?
这都是为了降低延迟的缘故。
随着现代应用程序对数据容量的要求在加大,需要提升TLB的大小来相应满足(TLB:
TranslationLookasideBuffer,旁路转换缓冲,或称为页表缓冲;里面存放的是虚拟地址到物理地址的转换表,供处理器以及具备分页机构的操作系统用来快速定位内存页面;大概很多人知道TLB是因为AMD的处理器TLBBug事件)。
Nehalem采用了较小的L1TLB附加一层较大的L2TLB的方法来解决这个问题(512个条目以覆盖足够大的内存区域,它仅用于较小的页面,指令和数据共用,两个线程共享)。
为了降低能耗,Nehalem架构将以往应用的Domino线路更换为StaticCMOS线路,并大规模使用了长沟道晶体管技术,速度有所降低,但是能源效率提升了
虽然如此,NehalemL1DCache的延迟仍然从Core2的3个时钟周期上升到了4个时钟周期,这是由于线路架构改变的缘故(从Domino更换成StaticCMOS,大量使用长沟到晶体管)。
类似地L1ICache乃至L2、L3的延迟都相应地会上升,然而指令缓冲的延迟对性能的影响要比数据严重;每一次取指令都会受到延迟影响,而缓存的延迟则可以通过乱序执行和猜测载入来解决。
因此Intel将L1ICache的集合关联从8路降低到4路,以维持延迟仍然在3个时钟周期。
Nehalem-EPXeonX5570的缓存结构:
64KBL1,256KBL2,8MB共享L3
TheMemorysub-System:
Cache
内存子系统:
缓存
与Core2相比,Nehalem新增加了一层L3缓存,这是为了多个核心共享数据的需要(Nehalem-EX具有8个核心),也因此这个L3的容量很大。
出于消除多核心共享数据的压力,前面的缓存不能让太多的缓存请求到达L3,而且L3的延迟(约30~40个时钟周期)和L1的延迟(3~4个时钟周期)相差太大,因此L2是很有必要的。
Nehalem简单地在很小的L1和大尺寸的L3之间插入256KB的L2来起到中继的作用——中继具有两个方面的含义:
容量和延迟。
256KB不算大,可以维持约低于10个时钟周期的延迟。
Nehalem的L2和L1不是包含也不是非包含的关系。
通常缓存具有两种设计:
非独占和独占,Nehalem处理器的L3采用了非独占高速缓存设计(或者说“包含式”,L3包含了L1/L2的内容),这种方式在CacheMiss的时候比独占式具有更好的性能,而在缓存命中的时候需要检查不同的核心的缓存一致性。
Nehalem并采用了“内核有效”数据位的额外设计,降低了这种检查带来的性能影响。
随着核心数目的逐渐增多(多线程的加入也会增加CacheMiss率),对缓存的压力也会继续增大,因此这种方式会比较符合未来的趋势。
在后面可以看到,这种设计也是考虑到了多处理器协作的情况(此时Miss率会很容易地增加)。
这可以看作是Nehalem与以往架构的基础不同:
之前的架构都是来源于移动处理设计,而Nehalem则同时为企业、桌面和移动考虑而设计。
在L3缓存命中的时候(单处理器上是最通常的情况,多处理器下则不然),处理器检查内核有效位看看是否其他内核也有请求的缓存页面内容,决定是否需要对内核进行侦听:
笔者相信这一点是不对的:
假如一个L3页面被多个内核共享(多于一个有效被设置为1),那么这个处理器的该页面就不能进入Modified状态
基于后面的NUMA章节的内容,多个处理器中的同一个缓存页面必定在其中一个处理器中属于F状态(可以修改的状态),这个页面在这个处理器中没有理由不可以多核心共享(可以多核心共享就意味着这个能进入修改状态的页面的多个有效位被设置为一)。
笔者相信MESIF协议应该是工作在核心(L1+L2)层面而不是处理器(L3)层面,这样统一处理器里多个核心共享的页面,只有其中一个是出于F状态(可以修改的状态)。
见后面对NUMA和MESIF的解析。
在L3缓存未命中的时候(多处理器下会频繁发生),处理器决定进行内存存取,按照页面的物理位置,它分为近端内存存取(本地内存空间)和远端内存存取(地址在其他处理器的内存的空间):
CacheMiss时而页面地址为本地的时候,处理器进行近端内存访问
延迟取本地内存访问和远程CPUCacheHit的延迟的最大值
CacheMiss时而页面地址为远程的时候,处理器进行远端内存访问
延迟取远程内存访问和远程CPUCacheHit的延迟的最大值
近端访问约60个时钟周期,远端访问约90个时钟周期(据说仍然比HarptertownXeon快),本地L3CacheHit则为30个时钟周期
TheUncore:
IMC
核外系统:
集成内存控制器
从形式上来看,L3缓存、集成的内存控制器乃至QPI总线都属于Uncore核外部分,从L2、L1一直到执行单元都属于Core核内部分。
由于Nehalem首次采用了这种核心内外的相对独立设计思路,因此核心之外的设计相对于Core架构来说显得新颖许多,这就是Nehalem的模块式设计。
模块式设计可以提供灵活的产品给用户,现在4核心、三通IMC和单QPI的桌面Nehalem已经面市,预计明年3月将会出现4核心、4通道IMC和双QPI的企业级Nehalem产品。
包含了PCIE控制器乃至集成显卡的产品也已经在路线上了。
继续回到处理器架构:
我们都知道,Nehalem和Intel以往处理器相比最大的特点就是直联架构——包括两个方面:
处理器直联以及内存直联,前者就是依靠QPI总线的实现,后者则是由于处理器内置了内存控制器(IMC,IntegratedMemoryController)。
当处理器在L3Cache未找到所要内容(L3CacheMiss)的时候,它将会继续通过IMC集成内存控制器往系统内存索取,同时通过QPI总线询问其他处理器(如果是多处理器平台)。
为什么直联架构可以很明显地提升性能?
这要先从x86架构的存储体系说起。
在很久很久以前,在一个记忆体短缺的时代——不仅仅处理器外面记忆体很少,处理器里面也是。
使用了CISC架构的x86处理器里面只有8个GPR通用寄存器(一般的RISC处理器有32个以上的通用寄存器,现在的x86-64有16个通用寄存器),由于通用寄存器数量上的短缺,因此不像RISC处理器那样,CISC的x86处理器使用了堆叠运算指令。
堆叠运算也就是将运算结果保存在源寄存器上的,如ADDAX,BX指令会将AX寄存器与BX寄存器的内容相加,并将结果保存到AX上——这样对比于使用三个寄存器做同一运算的非堆叠指令RISC架构就节约了一个寄存器,然而相应地源寄存器的内存就销毁了。
x86架构需要执行大量的Load/Store微指令(PentiumPro开始具备)来进行寄存器-寄存器或寄存器-内存之间的数据搬运操作。
RISC处理器当中,Load/Store操作也很频繁。
如前面所述,最常用的20条x86指令当中:
mov占35%(寄存器之间、寄存器与内存之间移动数据),push占10%(压入堆栈,也经常用来传递参数),call占6%,cmp占5%,add、pop、lea占4%(实际计算指令非常少)
mov、push、pop都是和load/store直接相关的,add、cmp等则间接相关
顺便:
75%的x86指令短于4bytes,也就是小于32bits。
不过这些短指令只占代码大小的53%——有一些指令非常长
单操作数指令占37%,双操作数指令占60%
双操作数指令中,直接数操作20%,寄存器操作数56%,绝对寻址操作数1%,间接寻址操作数23%
Load操作占据了x86uops当中的约30%
大量的Load/Store操作已经通过ROB/MOB降低到一定程度,不过,在多核心/超线程的情况下,对缓存/内存子系统仍然具有很大的压力
现在来看这样的设计简直是无法想象,不过这样脑残的设计不仅仅用到了今天,而且还加速到了一个不可思议的境界……在与各种RISC架构处理器的交锋也不落下风……回到架构上,由于x86架构实际上是通过耗费寄存器带宽及缓存-内存带宽来节约处理器内部寄存器数量,大量的Load/Store操作(Load操作占据了x86uops当中的约30%),对缓存乃至内存的性能非常依赖。
Nehalem具有三个Load/Store单元以及一个MOB架构,并支持内存数据相依性预测功能,缓存性能非常出色
缘此,x86架构在缓存-内存上的提升是不遗余力,不提2008年度评测报告:
深入Nehalem微架构中说到的内存数据相依性预测功能(MemoryDisambiguation),对于Nehalem而言,这方面最大的改进就是直联架构带来的IMC集成内存控制器,它使CPU到内存的路径更短,大幅度降低了内存的延迟,同时每一个CPU都具有自己专有的内存带宽。
这一点在数据库应用中表现非常显著,数据库应用对存储器的延迟很敏感。
TheUncore:
QPI
核外系统:
QPI
直联架构不仅仅意味着处理器与内存直接相连,还让处理器之间也直接联系起来。
Hyper-Transport总线的使用让Operton进入了高性能计算市场,QPI所作的事情是一样的。
通过QPI总线,处理器之间可以直接相连,不再需要经过拥挤、低带宽的FSB共享总线,多处理器系统运行效率大为提升。
对于多处理器系统而言,QPI提供的巨大带宽对性能提升很有作用。
QPI总线vsFSB总线
QPIvs.FSB
名称
IntelFSB(FrontSideBus)
IntelQuickPathInterconnect(QPI)
拓扑
共享总线
点对点连接
物理总线宽度(bits)
64
20x2(双向)
数据总线宽度(bits)
64
16x2(双向)
传输速率
333MHz
1.333GT/s
10.6GB/s
3.2GHz
6.4GT/s
12.8GB/s(单向)
25.6GB/s(双向)
需要边带信号
是
否
引脚数
150
84
时钟数
1
1
集成时钟
否
否
总线传输方向
双向
单向
使用高频率DDR3内存,访问本地内存的延迟大约为60个时钟周期,而通过QPI总线访问远端的处理器并返回数据大约需要90个时


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- intelNehalemEP 处理器 首发 深度 评测 第二 部分
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 转基因粮食的危害资料摘编Word下载.docx
转基因粮食的危害资料摘编Word下载.docx
-
高中英语词组大全Word文档下载推荐.docx
-
卫计局年工作总结及新年工作计划Word格式.docx
-
贵州省煤矿安全管理人员安全资格证A考试概况Word格式.docx
-
系统集成项目招标文件Word文件下载.docx
-
消防设计技术审查的要点Word文档格式.docx
-
第三章 习题课 带电粒子在磁场或复合场中的运动Word格式.docx
-
湖南岳阳中考英语模拟卷含答案Word文档格式.docx
-
电子商务考试题总汇打印版打印打印Word下载.docx
-
选调生考试备考言语理解与表达真题Word文档格式.docx
-
高考物理实验题专练 专练15Word文档格式.docx
-
加装奥迪A4L蓝牙电话功能Word文档下载推荐.docx
-
学年下学期好教育高三月考仿真卷A卷 语文 学生版后附详解Word文档下载推荐.docx
-
净化生产车间工程一般施工技术施工方案Word文档格式.docx
-
内蒙古呼和浩特市第六中学学年高一政治下学期期末考试试题Word下载.docx
-
证券行业客户经理电话营销技巧与实例Word文档下载推荐.docx
-
叶芝 苇间风文档格式.docx
-
最新中美贸易摩擦的原因及解决对策1论文Word文件下载.docx
-
意义的近义词Word格式文档下载.docx
-
上海市中考英语试题S.docx
-
专题12观点论证类设问.docx
-
附加安心重疾条款.docx
-
设计变更管理办法修改意见稿FINAL汇编.docx
-
毕业赠言毕业致词精选多篇.docx
-
银行新员工代表发言稿精选多篇.docx
-
北京市朝阳区届高三第一学期期末语文试题Word版含答案.docx
-
HL线切割使用说明书模板.docx
-
车工实训周记.docx
-
USBHID键盘扫描码.docx
-
Apmpoqu4调研报告.docx
-
最熟悉的陌生人作文八篇.docx
-
被动语态综合讲解.docx
-
CAXA操作说明.docx
-
C语言程序设计课程标准.docx
-
最新教师征文.docx
-
最新绿色生产管理制度汇编.docx
-
最新人力资源系统岗位能力测评考试完整版考核题库500题含参考答案.docx
-
最新硕士毕业论文的开题写作范例.docx
-
最新湘教版一至六年级古诗汇总.docx
-
最新一年级语文下册课文13荷叶圆圆教学设计.docx
-
最新中考语文第1部分积累与运用专题五文学文化常识与名著阅读作业淮安专版.docx
-
昨天今天明天作文精选15篇.docx
-
《宪法学》期末考试简答题论述题.docx
-
初一英语下册:unit 7 语法专项训练.docx
-
初中英语全部英语动词+doing和+to do 句型汇总.docx
-
《标准化智慧》速记.docx
-
《用心灵去倾听》公开课教学设计底稿.docx
-
《东方和西方的科学》导学案4最新教育文档.docx
-
《国际商务与国际营销》案例分析.docx
-
《中国好声音》导师考核.docx
-
《居住区环境景观设计导则试行稿》.docx
