 信息编码实验报告.docx
信息编码实验报告.docx
- 文档编号:6655585
- 上传时间:2023-01-08
- 格式:DOCX
- 页数:13
- 大小:104.89KB
信息编码实验报告.docx
《信息编码实验报告.docx》由会员分享,可在线阅读,更多相关《信息编码实验报告.docx(13页珍藏版)》请在冰豆网上搜索。
信息编码实验报告
实验1
一.实验名称:
Huffman编码.
二.实验时间:
2012.6.07
三.实验目的:
(1)进一步熟悉Huffman编码过程;
(2)掌握C语言的递归及调试技术.
四.实验原理:
哈夫曼编码的具体步骤归纳如下:
1概率统计(如对一幅图像,或m幅同种类型图像作灰度信号
统计),得到n个不同概率的信息符号。
②将n个信源信息符号的n个概率,按概率大小排序。
③将n个概率中,最后两个小概率相加,这时概率个数减为n-1个。
④将n-1个概率,按大小重新排序。
⑤重复③,将新排序后的最后两个小概率再相加,相加和与其余概率再排序。
⑥如此反复重复n-2次,得到只剩两个概率序列。
⑦以二进制码元(0.1)赋值,构成哈夫曼码字。
编码结束。
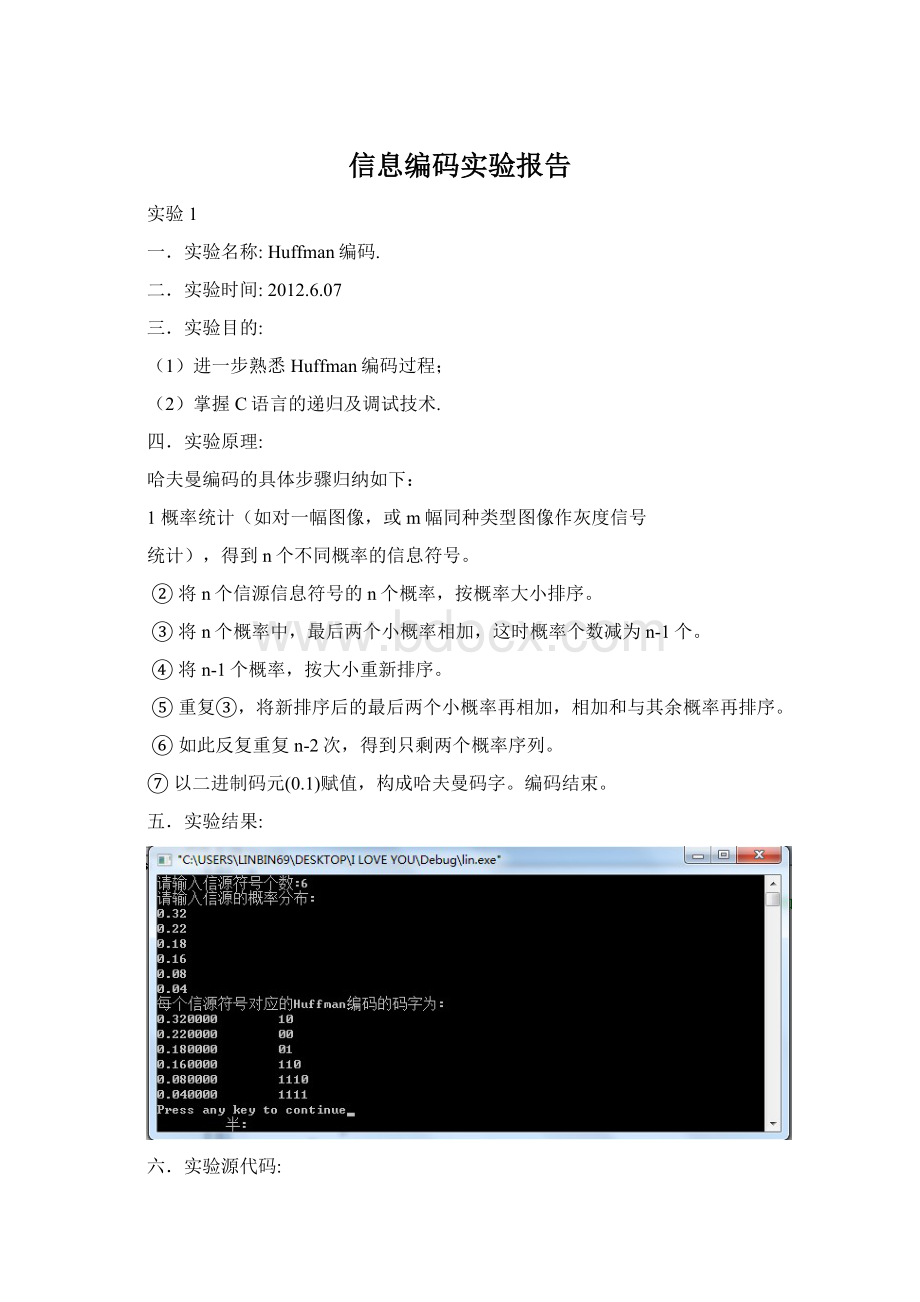
五.实验结果:
六.实验源代码:
#include
#include
#include
#include
#include
#include
#defineDELTA1.0e-6
//节点的结构体
typedefstruct
{floatweight;//结点权值
unsignedintparent,lchild,rchild;//结点的父指针,左右孩子指针
}HTNode,*HuffmanTree;//动态分配数组存储哈夫曼树
typedefchar**HuffmanCode;//动态分配数组存储哈夫曼编码表
voidCreateHuffmanTree(HuffmanTree&,float*,int);//生成哈夫曼树
voidHuffmanCoding(HuffmanTree,HuffmanCode&,int);//对哈夫曼树进行编码
voidPrintHuffmanCode(HuffmanCode,float*,int);//显示哈夫曼编码
voidSelect(HuffmanTree,int,int&,int&);//在数组中寻找权值最小的两个结点
voidmain()
{
HuffmanTreeHT;//哈夫曼树HT
HuffmanCodeHC;//哈夫曼编码表HC
intn,i;//n是哈夫曼树叶子结点数
floatsum=0;
float*w;//w存放叶子结点权值
printf("请输入信源符号个数:
");
scanf("%d",&n);//输入字符数目
if(n<=1)
{
printf("该数不合理!
\n");
}
w=(float*)malloc(n*sizeof(float));//开辟空间存放权值
printf("请输入信源的概率分布:
\n");
for(i=0;i { scanf("%f",&w[i]);//输入各字符出现的次数/权值 sum+=w[i]; } //提示输入错误 if(fabs(sum-1.0)>DELTA) { fprintf(stderr,"信号概率输入有误\n"); exit(-1); } for(i=0;i { CreateHuffmanTree(HT,w,n);//生成哈夫曼树 } HuffmanCoding(HT,HC,n);//进行哈夫曼编码 PrintHuffmanCode(HC,w,n);//显示哈夫曼编码 } //构造huffman树 voidCreateHuffmanTree(HuffmanTree&HT,float*w,intn) {//w存放n个结点的权值,将构造一棵哈夫曼树HT inti,m; ints1,s2; HuffmanTreep; if(n<=1)return; m=2*n-1;//n个叶子结点的哈夫曼树,有2*n-1个结点 HT=(HuffmanTree)malloc((m+1)*sizeof(HTNode));//开辟2*n各结点空间 for(p=HT+1,i=1;i<=n;++i,++p,++w)//进行初始化,给每个叶子节点赋值 { p->weight=*w; p->parent=0; p->lchild=0; p->rchild=0; } for(;i<=m;++i,++p) { p->weight=0; p->parent=0; p->lchild=0; p->rchild=0; } for(i=n+1;i<=m;++i)//建哈夫曼树 { Select(HT,i-1,s1,s2); //从HT[1...i-1]中选择parent为0且weight最小的两个结点,其序号分别为s1和s2 HT[s1].parent=i;HT[s2].parent=i;//修改s1和s2结点的父指针parent HT[i].lchild=s1;HT[i].rchild=s2;//修改i结点的左右孩子指针 HT[i].weight=HT[s1].weight+HT[s2].weight;//修改权值 } } voidHuffmanCoding(HuffmanTreeHT,HuffmanCode&HC,intn) {//将有n个叶子结点的哈夫曼树HT进行编码,所编的码存放在HC中 //方法是从叶子到根逆向求每个叶子结点的哈夫曼编码 inti,c,f,start; char*cd; HC=(HuffmanCode)malloc((n+1)*sizeof(char*));//分配n个编码的头指针向量 cd=(char*)malloc(n*sizeof(char));//开辟一个求编码的工作空间 cd[n-1]='\0';//编码结束符 for(i=1;i<=n;++i)//逐个地求哈夫曼编码 { start=n-1;//编码结束位置 for(c=i,f=HT[i].parent;f! =0;c=f,f=HT[f].parent)//从叶子到根逆向求编码 { if(HT[f].lchild==c) { start--; cd[start]='0';//若是左孩子编为'0' } else { start--; cd[start]='1';//若是右孩子编为'1' } } HC[i]=(char*)malloc((n-start)*sizeof(char));//为第i个编码分配空间 strcpy(HC[i],&cd[start]);//将编码从cd复制到HC中 } free(cd);//释放工作空间 } voidPrintHuffmanCode(HuffmanCodeHC,float*w,intn) {//显示有n个叶子结点的哈夫曼树的编码表 inti; printf("每个信源符号对应的Huffman编码的码字为: \n"); for(i=1;i<=n;i++) { printf("%f\t",w[i-1]); puts(HC[i]); } } voidSelect(HuffmanTreeHT,intt,int&s1,int&s2) {//在HT[1...t]中选择parent不为0且权值最小的两个结点,其序号分别为s1和s2 inti; floatm,n; m=n=1.0; for(i=1;i<=t;i++) { if(HT[i].parent==0&&(HT[i].weight { if(m { n=HT[i].weight;s2=i; } else { m=HT[i].weight;s1=i; } } } if(s1>s2)//s1放较小的序号 { i=s1;s1=s2;s2=i; } } 实验2 一.实验时间: 2012.6.10 二.实验名称: 唯一可译码判决准则. 三.实验目的: (1)进一步熟悉唯一可译码判决准则; (2)掌握C语言字符串处理程序的设计和调试技术. 四.实验要求: (1)已知: 信源符号个数q、码字集合C; (2)输入: 任意一个码。 码字个数和和每个具体的码字在运行是从键盘输入; (3)输出: 判决(是唯一可译码/不是唯一可译码); 五.算法 输入码字集合X0 for所有Wi,Wj∈X0 if码字Wi是码字Wj的前缀, 即将相应的后缀作为一个尾随后缀放入新集合X1 endif endfor for所有Wi∈X0 for所有Wj∈Xn-1 ifWi是Wj的前缀, 即将相应的后缀作为一个尾随后缀放入新集合Xn中 elseifWj是Wi的前缀, 即将相应的后缀作为一个尾随后缀放入新集合Xn中 endif endfor endfor 构造尾随后缀集合X←Xi if有码字Wi∈X0,Wi∈X,则非唯一可译码 六.实验结果: 七.实验源代码: #include #include #include structstrings { char*string; structstrings*next; }; structstringsFstr,*Fh,*FP; //输出当前集合 voidoutputstr(strings*str) { do { cout< str=str->next; }while(str); cout< } inlineintMIN(inta,intb) {returna>b? b: a;} inlineintMAX(inta,intb) {returna>b? a: b;} #definelength_a(strlen(CP)) #definelength_b(strlen(tempPtr)) //判断一个码是否在一个码集合中,在则返回0,不在返回1 intcomparing(strings*st_string,char*code) { while(st_string->next) { st_string=st_string->next; if(! strcmp(st_string->string,code)) return0; } return1; } //判断两个码字是否一个是另一个的前缀,如果是则生成后缀码 voidhouzhui(char*CP,char*tempPtr) { if(! strcmp(CP,tempPtr)) { cout<<"集合C和集合F中有相同码字: "< < <<"不是唯一可译码码组! "< exit (1); } if(! strncmp(CP,tempPtr,MIN(length_a,length_b))) { structstrings*cp_temp; cp_temp=new(structstrings); cp_temp->next=NULL; cp_temp->string=newchar[abs(length_a-length_b)+1]; char*longstr; longstr=(length_a>length_b? CP: tempPtr);//将长度长的码赋给longstr //取出后缀 for(intk=MIN(length_a,length_b);k cp_temp->string[k-MIN(length_a,length_b)]=longstr[k]; cp_temp->string[abs(length_a-length_b)]=NULL; //判断新生成的后缀码是否已在集合F里,不在则加入F集合 if(comparing(Fh,cp_temp->string)) { FP->next=cp_temp; FP=FP->next; } } } voidmain() { //功能提示和程序初始化准备 cout<<"\t\t唯一可译码的判断! \n"< structstringsCstr,*Ch,*CP,*tempPtr; Ch=&Cstr; CP=Ch; Fh=&Fstr; FP=Fh; charc[]="C: "; Ch->string=newchar[strlen(c)]; strcpy(Ch->string,c); Ch->next=NULL; charf[]="F: "; Fh->string=newchar[strlen(f)]; strcpy(Fh->string,f); Fh->next=NULL; //输入待检测码的个数 intCnum; cout<<"输入待检测码的个数: "; cin>>Cnum; cout<<"输入待检测码"< for(inti=0;i { cout< "; chartempstr[10]; cin>>tempstr; CP->next=new(structstrings); CP=CP->next; CP->string=newchar[strlen(tempstr)]; strcpy(CP->string,tempstr); CP->next=NULL; } outputstr(Ch); CP=Ch; while(CP->next->next) { CP=CP->next; tempPtr=CP; do { tempPtr=tempPtr->next; houzhui(CP->string,tempPtr->string); }while(tempPtr->next); } outputstr(Fh); structstrings*Fbegin,*Fend; Fend=Fh; while (1) { if(Fend==FP) { cout<<"是唯一可译码码组! "< exit (1); } Fbegin=Fend; Fend=FP; CP=Ch; while(CP->next) { CP=CP->next; tempPtr=Fbegin; for(;;) { tempPtr=tempPtr->next; houzhui(CP->string,tempPtr->string); if(tempPtr==Fend) break; } } outputstr(Fh);//输出F集合中全部元素 } }


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 信息 编码 实验 报告
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 铝散热器项目年度预算报告.docx
铝散热器项目年度预算报告.docx
-
牛津上海版通用小学英语三年级上册Unit 12同步练习2II 卷.docx
-
论我国私营企业员工激励机制.docx
-
人教版五年级品德与社会上册全册教案.docx
-
开学啦国旗下讲话稿三分钟.docx
-
露天采矿学复习题.docx
-
六年级英语教师年度考核个人总结.docx
-
某路站综合体项PC吊装施工方案.docx
-
人教版九年级历史上册期末考试试题一套.docx
-
隆昌妇幼保健院.docx
-
芦二矿抽采达标中长期规划.docx
-
看拼音写词语.docx
-
模拟磁盘调度算法系统的设计毕业设计.docx
-
每周一条名言警句或一首诗词.docx
-
棉花膜下滴灌示范工程设计总结报告.docx
-
九年级化学教案第十单元酸和碱教案新人教版.docx
-
宁波市水资源公报.docx
-
农业实用技术培训工作意见与农业局上半年工作总结范例两篇汇编.docx
-
平行线的判定.docx
-
内部会计管理制度11成本核算制度.docx
-
盘扣式脚手架支撑方案.docx
-
旅游规划模板.docx
-
煤矿大本大专毕业设计大采高综采工作面作业规程.docx
-
美学选择题整理课件资料.docx
-
名家论腹泻慢性肠炎.docx
-
宁夏银川市第一中学学年高一上学期期中考试地理试题解析解析版.docx
-
年产吨精密纤维纸项目建设建议书.docx
-
农技推广中心工作总结.docx
-
彭宇案的法逻辑批判.docx
-
宁夏仕奇房产网发布份房地产交易情况.docx
-
项目推荐书智能温控节能系统.docx
-
区县节日期间加强消防安全讲话稿与区发改委领导班子述职述廉报告汇编.docx
-
完整word版中国石油大学华东油田化学综合复习题docx.docx
-
葡萄的副梢管理技术.docx
-
天津一中高三年级四月考.docx
-
环境化学重点内容_精品文档.doc
-
环境保护职业健康与安全技术交底书人工挖孔桩_精品文档.doc
 XRD教程培训教程文件.ppt
XRD教程培训教程文件.ppt
-
玛利亚别墅的各种处理分析.docx
-
蒲柳人家课文.docx
-
小学毕业作文复习100题.docx
-
一级结构工程师基础考试doc.docx
-
智慧树知到《精神病学》章节测试答案.docx
-
优秀医师奖励方案.docx
-
原料采购合同新.docx
-
水利工程建设质量保证体系监理.docx
-
完整版图形的运动教案.docx
-
铁塔监控告警处理方法.docx
-
中国松茸行业研究与投资分析报告.docx
-
小学六年级不规则动词过去式过去分词表规则不规则样本.docx
-
一年级下册健康教育.docx
