 第二次实验 数据定义语言DDL.docx
第二次实验 数据定义语言DDL.docx
- 文档编号:30694100
- 上传时间:2023-08-19
- 格式:DOCX
- 页数:17
- 大小:1.37MB
第二次实验 数据定义语言DDL.docx
《第二次实验 数据定义语言DDL.docx》由会员分享,可在线阅读,更多相关《第二次实验 数据定义语言DDL.docx(17页珍藏版)》请在冰豆网上搜索。
第二次实验数据定义语言DDL
数据库课程实验报告
姓名
学号
系
计算机科学与技术
任课教师
黄秋颖
指导教师
黄秋颖
评阅教师
黄秋颖
实验地点
实验时间
实验编号与实验名称:
数据定义语言DDL
实验目的:
了解数据库
实验内容及要求(详见实验讲义):
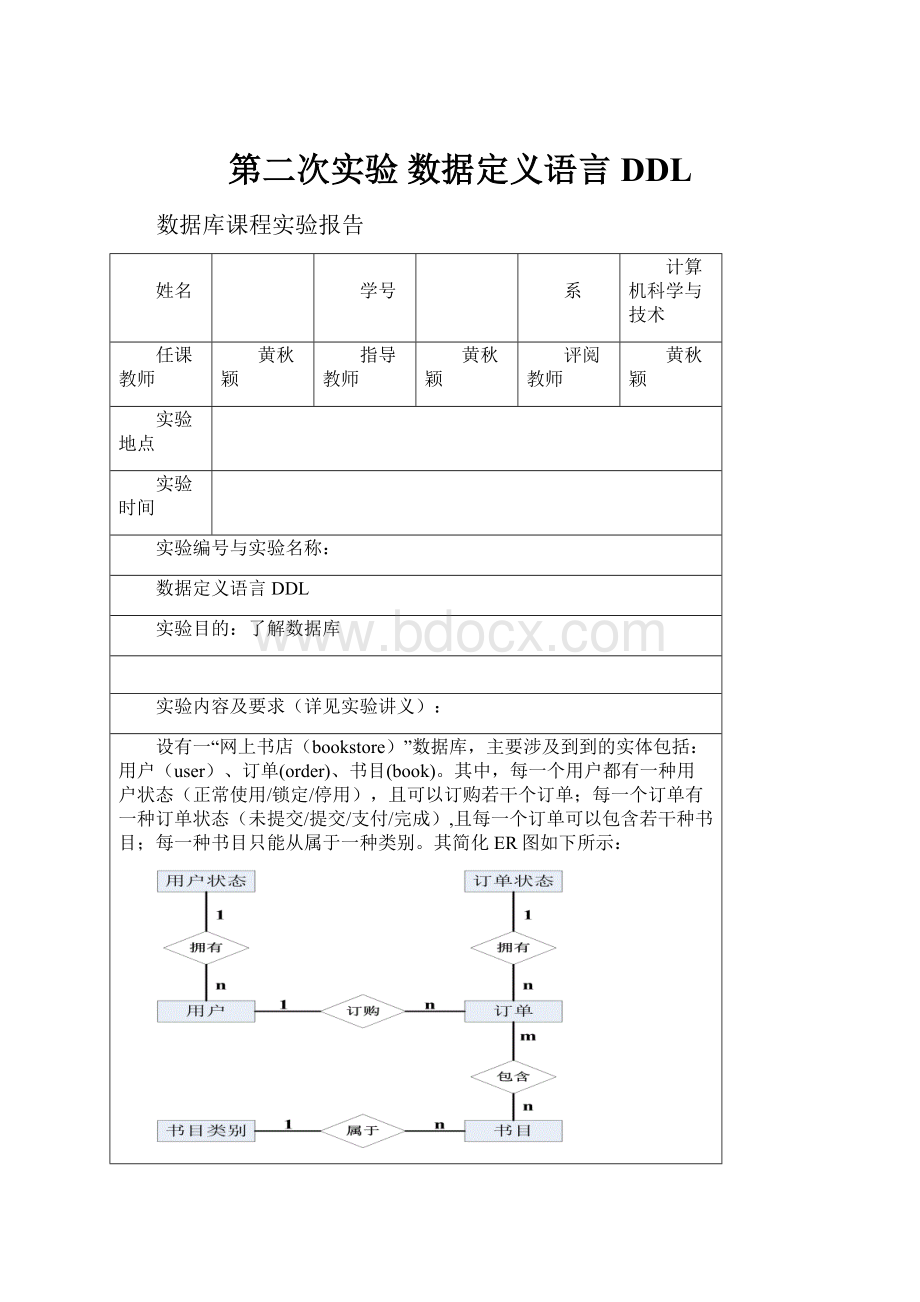
设有一“网上书店(bookstore)”数据库,主要涉及到到的实体包括:
用户(user)、订单(order)、书目(book)。
其中,每一个用户都有一种用户状态(正常使用/锁定/停用),且可以订购若干个订单;每一个订单有一种订单状态(未提交/提交/支付/完成),且每一个订单可以包含若干种书目;每一种书目只能从属于一种类别。
其简化ER图如下所示:
实验用到的软件(SQLServerManagementStudio)
实验内容、关键步骤(流程图、代码等)及结果分析(70分)
1.创建数据库表
验证结果
2.修改表
(1)给用户表增加一个“出生日期”(birthday)字段,数据类型为datetime,不为空。
(2)给订单表增加一个“总付款”(payment)字段,数据类型为float,默认值为0。
(3)给订单表增加一个“提交时间”(ordertime)字段,数据类型为datetime。
(4)给书目表增加如下约束条件:
stock必须大于0。
(5)给订单详情表增加相应约束条件:
quantity默认值为1,且必须大于0。
(6)给用户表增加相应约束条件:
name必须为唯一。
加约束条件最值,不需要加addconstraint。
加约束条件为唯一值才需要。
3.插入数据
结果验证
5.创建索引
(1)在用户表的“name”列上创建一个唯一值、聚簇索引IX_user_name。
能否创建成功?
为什么?
答:
不能。
每个表只能有一个聚簇索引,因为一个表中的记录只能以一种物理顺序存放。
(2)在订单表“state”列上创建一个非唯一性值、非聚簇索引IX_order_state。
观察创建索引后,数据表中的数据有何变化?
为什么?
可以。
得重新输入select语句查找orderStateId,数据会进行排序,不能直接按设计看,因为排序结果是由主键主导。
因为非聚簇索引则没有按序存放,需要额外消耗资源来排序。
实验过程中遇到的问题解决办法与实验体会(10分)【请注意:
此处必须如实填写,为空或不适均扣10分】
思考题:
(1)CREATETABLE在创建表时,通常还可以定义与该表有关的完整性约束条件。
ALTERTABLEtablenameADDINDEX[索引的名字](列的列表),用来修改表
CREATEINDEXONtablename(列的列表),用来创建索引
(2)索引作用:
a)快速取数据;
b)保证数据记录的唯一性;
c)实现表与表之间的参照完整性;
d)在使用ORDERby、groupby子句进行数据检索时,利用索引可以减少排序和分组的时间。
每个表只能有一个聚簇索引,因为一个表中的记录只能以一种物理顺序存放。
但是,一个表可以有不止一个非聚簇索引。
唯一性索引,不允许具有索引值相同的行,从而禁止重复的索引或键值。
系统在创建该索引时检查是否有重复的键值,并在每次使用INSERT或UPDATE语句添加数据时进行检查。
创建唯一约束时会自动创建。
聚簇索引的叶节点就是数据节点,而非聚簇索引的叶节点仍然是索引节点,并保留一个链接指向对应数据块。
聚簇索引主键的插入速度要比非聚簇索引主键的插入速度慢很多。
相比之下,聚簇索引适合排序,非聚簇索引不适合用在排序的场合。
因为聚簇索引本身已经是按照物理顺序放置的,排序很快。
非聚簇索引则没有按序存放,需要额外消耗资源来排序。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 第二次实验 数据定义语言DDL 第二次 实验 数据 定义 语言 DDL
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 #2机组现场施工用电布置措施.docx
#2机组现场施工用电布置措施.docx
-
《个人贵金属质押借款合同》兴业银行.docx
-
《科学发展观和小康社会的经济建设》复习导学案.docx
-
《我和祖父的园子》第一课时教案两篇word.docx
-
《质量》教学案例与设计.docx
-
2惠农小册子.docx
-
7A版个人与团队模拟考试题及答案.docx
-
10篇新部编四年级下册语文课内外阅读理解专项练习题及答案.docx
-
16初四物理热和能知识点总结精讲.docx
-
20XX社会语言经典语录流行风暴.docx
-
48篇教学案例分析报告题.docx
-
《电子工厂安全管理制度汇总》.docx
-
《机械制造课程设计》指导.docx
-
《钱学森》教案第二课时.docx
-
《边城》读后感5篇.docx
-
《固定式压力容器安全技术监察规程》.docx
-
《论雷峰塔的倒掉》.docx
-
《手术台就是阵地》教学设计三年级语文下册.docx
-
《夏洛的网》课外阅读教学设计.docx
-
《自己的花是让别人看的》教案.docx
-
3C检查表090429.docx
-
7客运专线CRTSⅡ型板式无砟轨道施工工法.docx
-
《笔算除法》课时教案设计.docx
-
11#楼高大模板支撑体系专项方案.docx
-
17科学分析经济形势.docx
-
《电流和电路》易错题精讲综合检测题与答案.docx
-
《会计信息系统》习题含答案.docx
-
《汽车电器设备与维修》发电机分教考分离试题及标准答案.docx
-
《四川省排污许可证管理暂行办法》.docx
-
《新编实用英语》教案第一册Unit.docx
-
0母版锅炉值班员计算题WORD版.docx
-
3年级下册英语单词记忆人教版.docx
-
20XX中级会计考试真题经济法中级会计职称考试doc.docx
-
柳树镇卫生院人事制度改革实施方案.docx
-
最新小学英语六年级下课课练.docx
-
高考全国二卷历史试题及答案.docx
-
工程力学一.docx
-
学年第二学期初中毕业生升学模拟考试理科综合化学部分卷.docx
-
医药企业行业新版质量管理手册资料.docx
-
大学教室照明改造方案.docx
-
《高中美术课堂有效教学策略的研究》开题报告和结题报告.docx
-
防微振基础施工方案改.docx
-
沪粤版八年级下册物理知识点总结.doc
-
部编语文六年级上册第七单元复习卷word版含答案课内外阅读.docx
-
龙湖地产示范区各阶段设计导则.docx
-
大学生的创业计划书模板通用版.docx
-
工程造价分析论文.docx
-
学生升旗下的讲话稿5篇.docx
-
大学生返乡农村成功创业故事.docx
-
银行保安人员年终工作总结.docx
-
中医妇科学期末考试试题及答案.docx
