 扩频系统的仿真.docx
扩频系统的仿真.docx
- 文档编号:8471807
- 上传时间:2023-01-31
- 格式:DOCX
- 页数:20
- 大小:1,007.80KB
扩频系统的仿真.docx
《扩频系统的仿真.docx》由会员分享,可在线阅读,更多相关《扩频系统的仿真.docx(20页珍藏版)》请在冰豆网上搜索。
扩频系统的仿真
7.5扩频系统的仿真
7.5.1伪随机码的产生
Simulink通信库中提供了多种伪随机码信源模块,这些模块的简单介绍参见第3章的叙述。
下面重点讨论扩频系统中最常见的两种伪随机序列:
m序列和Gold码序列。
7.5.1.1线性反馈移位寄存器的结构和多项式表示
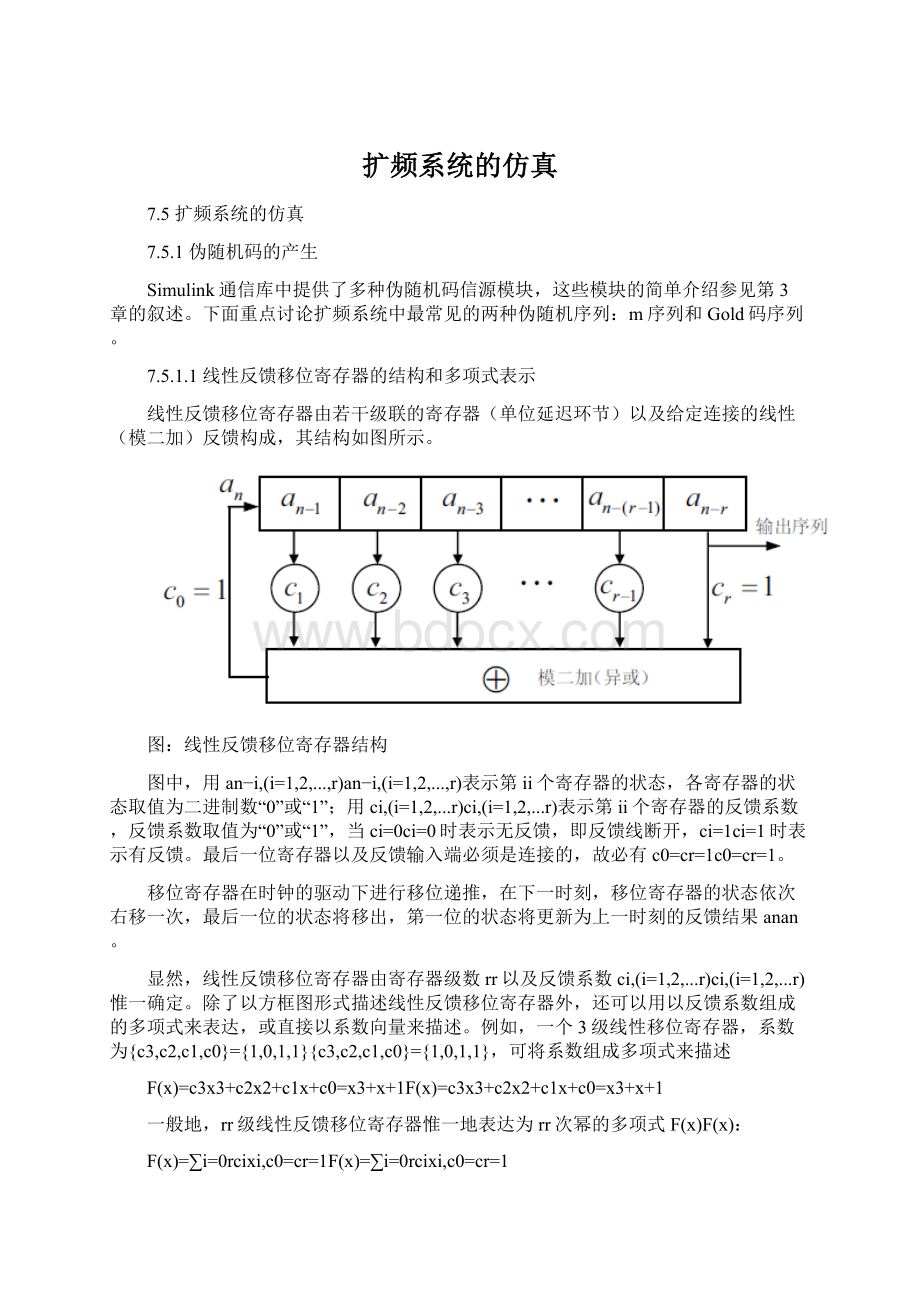
线性反馈移位寄存器由若干级联的寄存器(单位延迟环节)以及给定连接的线性(模二加)反馈构成,其结构如图所示。
图:
线性反馈移位寄存器结构
图中,用an−i,(i=1,2,...,r)an−i,(i=1,2,...,r)表示第ii个寄存器的状态,各寄存器的状态取值为二进制数“0”或“1”;用ci,(i=1,2,...r)ci,(i=1,2,...r)表示第ii个寄存器的反馈系数,反馈系数取值为“0”或“1”,当ci=0ci=0时表示无反馈,即反馈线断开,ci=1ci=1时表示有反馈。
最后一位寄存器以及反馈输入端必须是连接的,故必有c0=cr=1c0=cr=1。
移位寄存器在时钟的驱动下进行移位递推,在下一时刻,移位寄存器的状态依次右移一次,最后一位的状态将移出,第一位的状态将更新为上一时刻的反馈结果anan。
显然,线性反馈移位寄存器由寄存器级数rr以及反馈系数ci,(i=1,2,...r)ci,(i=1,2,...r)惟一确定。
除了以方框图形式描述线性反馈移位寄存器外,还可以用以反馈系数组成的多项式来表达,或直接以系数向量来描述。
例如,一个3级线性移位寄存器,系数为{c3,c2,c1,c0}={1,0,1,1}{c3,c2,c1,c0}={1,0,1,1},可将系数组成多项式来描述
F(x)=c3x3+c2x2+c1x+c0=x3+x+1F(x)=c3x3+c2x2+c1x+c0=x3+x+1
一般地,rr级线性反馈移位寄存器惟一地表达为rr次幂的多项式F(x)F(x):
F(x)=∑i=0rcixi,c0=cr=1F(x)=∑i=0rcixi,c0=cr=1
注意,其中加法是定义在2元有限域上的,即模二加法。
F(x)F(x)称为该线性反馈移位寄存器的生成器多项式(GeneratorPolynomial)或特征多项式。
多项式也可以用其系数向量直接表达出来,例如多项式
F(x)=x8+x6+x5+x4+1F(x)=x8+x6+x5+x4+1
可表示为系数向量[1,0,1,1,1,0,0,0,1][1,0,1,1,1,0,0,0,1]或非零系数所在幂次向量[8,6,5,4,0][8,6,5,4,0]。
为了便于书写,有些书上将系数向量以最右边一个为最低位,每三位写做一个八进制数,如以八进制数561561表示该多项式系数。
也有将系数向量视为一个二进制数而直接转换为十进制整数来表达,例如该多项式也可以用十进制整数369369惟一表示。
总之,只要表示结果与多项式系数是惟一对应关系即可。
7.5.1.2最大周期线性移位寄存器序列---m序列
一个rr级二进制移位寄存器最多可以取2r2r个不同的状态。
对于线性反馈(模二加运算),其中全零状态将导致反馈始终为零,成为一个全零状态死循环。
如果剩余的2r−12r−1个状态构成一个循环,即该循环以N=2r−1N=2r−1为周期,则称该循环输出序列为最大周期线性移位寄存器序列(简称m序列)。
不是任意的特征多项式对应的反馈连线都能够生成m序列。
能够产生m序列的充要条件是其特征多项式必须为本原多项式(primitivepolynomial),即rr次特征多项式F(x)F(x)同时满足以下三条件:
1. F(x)F(x)是不可约的(irreducible),即不能再进行因式分解。
2. F(x)F(x)可整除1+xN1+xN,其中N=2r−1N=2r−1。
3. F(x)F(x)除不尽1+xq1+xq,其中q 寻找本原多项式的计算较复杂,一般扩频通信的书籍中会给出本原多项式系数表(通常以八进制数来表示系数),Matlab通信工具箱中也提供了计算和判别本原多项式的函数,可计算的多项式次数rr在2到16之间。 根据多项式次数rr求出本原多项式的函数“primpoly”的用法是: pr=primpoly(r,'all')%得出所有r次本原多项式 pr=primpoly(r,'min')%得出反馈抽头数最少(多项式非零系数最少)的r次本原多项式 pr=primpoly(r,'max')%得出反馈抽头数最多的r次本原多项式 例如: >>pr=primpoly(4,'all')%得出所有4次本原多项式Primitivepolynomial(s)= D^4+D^1+1 D^4+D^3+1 pr= 19 25 得到4次本原多项式有两个,系数分别是(十进制表示)19和25。 如果需要用八进制或二进制表示,可用函数“str=dec2base(d,base)”转换,其中“base”参数为指定进制数,例如将十进制数19转换为二进制和八进制字符串: >>str=dec2base(19,2) str=10011%二进制 >>str=dec2base(19,8) str=23%八进制 如果给定多项式整数表示,判别对应的是否是本原多项式,可通过函数“isprimitive”进行,其用法是: B=isprimitive(a)%a为指定的多项式十进制系数表示 %如果返回1,表明是本原多项式,返回0,表示不是本原的。 〔实例7.21〕判断特征多项式 F(x)=x9+x6+x4+x3+1F(x)=x9+x6+x4+x3+1 是否可生成m序列,并建模验证。 F(x)F(x)对应的系数二进制表示为1001011001,相应的十进制数是601。 B=isprimitive(601) B= 1%是本原多项式 Simulink通信模块库中提供的“PNSequenceGenerator”用来产生线性移位寄存器序列,其设置参数为特征多项式(GeneratorPolynomial),寄存器初始状态,输出偏移量,采样时间间隔以及输出数据格式和是否具有复位端等,其中特征多项式可用两种形式之一表达,例如本例的特征多项式表达为[1,0,0,1,0,1,1,0,0,1]或[9,6,4,3,0]。 图: 线性移位寄存器序列的测试模型 测试模型如上图所示,其中使用了“PNSequenceGenerator”模块产生线性移位寄存器序列,其生成器多项式设置为{[}9,6,4,3,0],初始状态设置为全“1”: {[}ones(1,9)],采样时间设置为1秒,偏移量设为0。 当寄存器状态再次回到全“1”时,输出序列开始下一个周期。 因此可用检测输出序列连“1”个数来测量序列的周期。 图中“buffer”模块设置缓存区为9,重叠区为8,这样每隔1秒钟进入一个数据,且缓存最近的8个数据,当出现9个连“1”时,缓存器中将为全1,以点积“DotProduct”模块完成缓存区数据求和输出,若求和结果为9则判断序列中已经出现9个连“1”时,以门限为8.5的“Relay”模块完成判断。 最后在示波器上输出序列以及判断结果脉冲,脉冲周期即为序列周期。 其仿真结果如图所示,可见序列周期为511秒,等于29−129−1,所以是m序列。 图: 线性移位寄存器序列测试仿真结果 7.5.1.3伪随机序列的相关函数 周期为NN的取值为{±1}{±1}的两电平序列{a|a1,a2,...aN,aN+1,...}{a|a1,a2,...aN,aN+1,...}和{b|b1,b2,...bN,bN+1,...}{b|b1,b2,...bN,bN+1,...}的互相关函数定义为 Rab(j)=∑i=1Naibi+jRab(j)=∑i=1Naibi+j 以序列周期进行归一化后得到互相关系数的定义 ρab(j)=1N∑i=1Naibi+jρab(j)=1N∑i=1Naibi+j 如果{a}{a},{b}{b}为同一序列,则记Rab(j)Rab(j)为Ra(j)Ra(j),ρab(j)ρab(j)为ρa(j)ρa(j),称为自相关函数和自相关系数。 计算序列的相关函数时,应注意其周期性质,即对于周期为NN的序列,有aN+k=akaN+k=ak。 〔实例7.22〕计算特征多项式为 F(x)=x9+x6+x4+x3+1F(x)=x9+x6+x4+x3+1 的m序列的自相关系数。 对于周期NN的序列,其自相关系数是偶函数,即ρ(−j)=ρ(j)ρ(−j)=ρ(j),而且也是以NN为周期的周期函数。 周期为NN的m序列自相关系数理论值为 ρ(j)={1,−1N,j=kN,k=0,1,2,...j≠kNρ(j)={1,j=kN,k=0,1,2,...−1N,j≠kN 其中kk为整数。 本例中m序列的周期为N=29−1=511N=29−1=511,首先计算出一个周期的m序列,然后再根据自相关系数的定义进行计算,计算中应注意将二进制输出的m序列转换为取值{±1}{±1}的双极性序列,然后再求相关函数。 程序如下: 〔程序代码〕ch7example22prog1.m %ch7example22prog1.m clear; reg=ones(1,9);%寄存器初始状态: 全1,寄存器级数为9 coeff=[1,0,0,1,0,1,1,0,0,1];%抽头系数a0a1...ar,取决于特征多项式 N=2^length(reg)-1;%周期 fork=1: N%计算一个周期的m序列输出 a_n=mod(sum(reg.*coeff(1: length(coeff)-1)),2);%反馈系数 reg=[reg(2: length(reg)),a_n];%寄存器移位,反馈 out(k)=reg (1);%寄存器最低位输出 end out=2*out-1;%转换为双极性序列 forj=0: N-1 rho(j+1)=sum(out.*[out(1+j: N),out(1: j)])/N; end j=-N+1: N-1; rho=[fliplr(rho(2: N)),rho]; plot(j,rho);axis([-1010-0.11.2]); 计算结果与理论值相同,图形如下。 〔实例7.23〕计算r=6r=6本原多项式(八进制表示)103和147对应的两个m序列的互相关函数序列。 八进制数103和147转换为二进制分别是: 1000011和1100111。 对应m序列的特征多项式以向量形式表示为 [1,0,0,0,0,1,1][1,0,0,0,0,1,1] 和 [1,1,0,0,1,1,1][1,1,0,0,1,1,1] 参照实例7.22编写计算程序如下。 〔程序代码〕ch7example23prog1.m %ch7example23prog1.m clear; reg=ones(1,6);%寄存器初始状态: 全1,寄存器级数为6 coeff=[1,0,0,0,0,1,1];%抽头系数cr...c1c0,取决于特征多项式 N=2^length(reg)-1;%周期 fork=1: N%计算一个周期的m序列输出 a_n=mod(sum(reg.*coeff(1: length(coeff)-1)),2);%反馈 reg=[reg(2: length(reg)),a_n];%寄存器移位,反馈 out1(k)=2*reg (1)-1;%寄存器最低位输出,转换为双极性序列 end reg=ones(1,6); coeff=[1,1,0,0,1,1,1];%抽头系数 fork=1: N%计算一个周期的m序列输出 a_n=mod(sum(reg.*coeff(1: length(coeff)-1)),2);%反馈 reg=[reg(2: length(reg)),a_n];%寄存器移位,反馈 out2(k)=2*reg (1)-1;%寄存器最低位输出,转换为双极性序列 end %得出两个双极性电平的m序列 forj=0: N-1 R(j+1)=sum(out1.*[out2(1+j: N),out2(1: j)]);%计算相关函数 end j=-N+1: N-1;%相关函数自变量 R=[fliplr(R(2: N)),R];%利用相关函数的偶函数特性计算j为负值的情况 plot(j,R);axis([-NN-2020]);xlabel('j');ylabel('R(j)');%作图 max(abs(R))%计算相关函数绝对值的最大值 程序运行后得出互相关函数序列,如图所示,其绝对值的最大值为17。 图: 两个m序列的互相关函数计算结果 相同周期的不同m序列之间的互相关函数绝对值的最大值|Rab|max|Rab|max是不同的,我们希望互相关值越小越好,如果一对同周期的m序列的互相关值满足如下不等式,称这对m序列构成一优选对, |Rab(j)|max≤{2r+12+12r+22+1r为奇数r为偶数,但不被4整除|Rab(j)|max≤{2r+12+1r为奇数2r+22+1r为偶数,但不被4整除 显然,对于实例7.23中的两个m序列的互相关函数满足上式,故构成一个优选对。 m序列优选对一般是通过计算机进行数值计算来寻找的。 7.5.1.4Gold序列 Gold序列是由一对m序列优选对作模二加得到的。 设有一对周期为N=2r−1N=2r−1的m序列优选对{a}{a},{b}{b},以其中任意一个序列为基准序列,如{a}{a},对另一序列{b}{b}进行移位ii次,得到{b}{b}的移位序列{bi}{bi},然后与序列{a}{a}进行模二加一个新的周期为NN的序列{ci}{ci},称新序列{ci}{ci}为Gold序列。 即 {ci}={a}+{bi}i=0,1,...,N{ci}={a}+{bi}i=0,1,...,N 不同的移位值ii将得出不同的Gold序列,这样一对m序列优选对将可得出N=2r−1N=2r−1个不同的Gold序列,将这些Gold序列连同优选对m序列{a}{a},{b}{b}一共2r+12r+1个序列组成的集合成为一个Gold码族。 我们希望Gold序列一个周期中的“1”和“0”个数尽可能接近。 由于伪随机序列的周期N=2r−1N=2r−1总是奇数,故一个周期中的“1”和“0”个数最接近的情况是相差为1,这样的Gold码称为平衡码。 〔实例7.24〕以r=11r=11的m序列优选对特征多项式4005和7335(八进制表示)产生Gold码,并验证当第一个m序列(4005)初始状态{an−1,...,an−r}{an−1,...,an−r}为{[}0,0,0,0,0,0,0,0,0,0,1],第二个m序列(7335)初始状态为任意但不全为零。 变化第二个m序列的初始状态,试计算出一个周期内“1”和“0”的个数差分布以及平衡码的个数。 两个m序列的特征多项式分别为: 4005: Fa(x)7335: Fb(x)==x11+x2+1x11+x10+x9+x7+x6+x4+x3+x2+14005: Fa(x)=x11+x2+17335: Fb(x)=x11+x10+x9+x7+x6+x4+x3+x2+1 设计的计算程序如下,其中使用了函数编程形式,以子函数形式产生m序列、Gold码以及寄存器状态的十进制数表示与二进制数组表示之间的转换。 改变寄存器状态后分别计算出Gold码的一个周期,然后统计其中“1”和“0”的个数差并显示。 〔程序代码〕ch7example24func.m %ch7example24func.m functiondiff_of_1_0=ch7example24func() reg1=[10000000000];%寄存器初态(从低到高位a_(n-r),...,a_(n-1)) coeff1=[100000000101];%抽头系数crcr-1...c0,取决于特征多项式: 4005 coeff2=[111011011101];%抽头系数crcr-1...c0: 7335 diff_of_1_0(2^11)=0;%1和0个数差值存储数组初始化 forL=1: (2^11-1) reg2=decinttobin(L,11);%寄存器组2的状态 gold=gld_seq_gen(reg1,coeff1,reg2,coeff2); num_of_1=sum(gold);%统计其中1的个数 num_of_0=sum(1-gold);%统计其中0的个数 diff_of_1_0(L)=num_of_1-num_of_0;%返回1和0个数差值 end banlanceGoldNum=sum(diff_of_1_0==1)%计算并显示1和0个数差值 Num65=sum(diff_of_1_0==65) NumNeg63=sum(diff_of_1_0==-63) %以下是本函数内部使用的子函数: m序列、Gold序列和进制转换 %m序列计算函数 functionm=m_seq_gen(reg,coeff) fork=1: (2^length(reg)-1)%计算一个周期的m序列输出 a_n=mod(sum(reg.*coeff(1: length(coeff)-1)),2);%反馈 m(k)=reg (1);%寄存器最低位输出 reg=[reg(2: length(reg)),a_n];%寄存器移位,反馈 end %Gold序列计算函数 functiong=gld_seq_gen(reg1,coeff1,reg2,coeff2) m1=m_seq_gen(reg1,coeff1);%第一个m序列 m2=m_seq_gen(reg2,coeff2);%第二个m序列 g=mod(m1+m2,2);%模二加得到Gold序列 %进制转换函数 functionbinvec=decinttobin(x,d)%将十进制整数转换为二进制数存放在矩阵中 %d为指定的转换二进制位数 fork=0: d-1 binvec(d-k)=rem(x,2); x=floor(x/2); end 程序调用执行后结果是: diff_of_1_0=ch7example24func; banlanceGoldNum=1023%平衡码数 Num65=496%"1"比"0"多65个的序列数 NumNeg63=528%"1"比"0"少63个的序列数 显然,其中平衡Gold码有1023个,约占总码数的1/21/2,其余两种非平衡码各占约总数的1/41/4。 7.5.2直接序列扩频系统 直接序列扩频的发射机系统结构如图所示。 图: 直接序列扩频的发射机系统结构 其中设数据序列{an}{an}对应的双极性波形为a(t)a(t),其电平取值为±1±1,码元速率为RaRabps,码元宽度为Ta=1/RaTa=1/Ra秒。 扩频所使用的伪随机序列c(t)c(t)也是电平取值为±1±1的双极性波形,伪随机序列的码元也称为码片(chip),码片速率设为RcRcchip/s,对应的码片宽度就是Tc=1/RcTc=1/Rc秒。 码片速率通常是数据速率的整数倍,且Rc/Ra≫1Rc/Ra≫1。 对于双极性波形而言,扩频过程等价于数据流a(t)a(t)与伪随机序列c(t)c(t)相乘的过程,扩频输出序列设为d(t)d(t),也是取值为±1±1的双极性波形,其速率等于码片速率。 扩频序列经过调制后得到调制输出信号s(t)s(t)送入信道。 对于BPSK调制,有 s(t)=d(t)cos2πfct=a(t)c(t)cos2πfcts(t)=d(t)cos2πfct=a(t)c(t)cos2πfct 由于PN码速率远远高于数据传输速率,所以调制输出信号s(t)s(t)的频带宽度将远远大于数据波形的带宽。 〔实例7.25〕设数据传输率为Ra=100Ra=100bps,扩频码片速率为Rc=2000Rc=2000chip/s,Rc/Ra=20Rc/Ra=20,采用m序列作为扩频序列,以BPSK为调制方式。 试建立扩频系统仿真模型并仿真观察其数据波形、扩频输出波形以及扩频调制输出的频谱。 仿真模型如图所示,“BernoulliBinaryGenerator”产生数据流,其采样时间设置为0.01秒,这样输出的数据速率为100bps。 “PNSequenceGenerator”产生伪随机扩频序列,其采样时间设置为0.0005秒,这样输出的码片速率为2000chip/s。 为了使得扩频模块(乘法器)上的数据采样速率相同,需要对数据流进行升速率处理。 “UnipolartoBipolarConverter”完成数据和扩频序列的双极性变换。 乘法器输出即为扩频输出,其码速率等于采样速率,即每个采样点代表一个码片。 扩频输出信号以BPSK方式进行调制。 图: 直接扩频发射机仿真系统模型 仿真执行后,两个频谱仪将分别显示扩频前后的信号频谱,采用BPSK调制的等效低通模型时,调制前后的功率频谱相同,为了便于对比,我们将两个频谱仪显示图形重叠在一起绘出,如图所示,可见,数据信号的带宽约100Hz,其功率峰值约为20dB,而扩频输出信号带宽展宽了20倍,为2KHz,而其功率峰值下降到约7dB处。 图: 直接扩频发射机扩频前后的信号频谱仿真结果 仿真输出的时域波形结果如图所示,图中显示了数据流、PN序列以及扩频输出信号的波形,当数据为+1+1时,扩频输出就是对应的PN序列,当数据为−1−1时,扩频输出是PN序列的反相结果。 图: 直接扩频发射机扩频前后的信号波形仿真结果 最后,可将模型中虚线部分封装起来作为一个扩频发射子系统备用。 直接序列扩频系统的信道以及接收机结构如图所示。 图: 直接扩频系统传输信道以及接收机系统方框图 在信道中,信号被叠加了噪声和干扰,这里干扰通常指敌方的恶意干扰或通信用户之间的相互干扰等,噪声则指由多种微小的随机因素所造成的综合结果。 干扰可分为单频正弦波干扰、脉冲干扰、多用户干扰等等,而噪声在理论分析和计算中一般建模为高斯的。 接收机前端电路系统包含高频放大、混频、中频放大等部分,目的是将接收的微弱信号进行放大和频率搬移以满足后级(解扩)的信号处理要求。 设信道中等效噪声为n(t)n(t),干扰为J(t)J(t),则接收机前端电路系统输出信号r(t)r(t)可建模为 r(t)=s(t)+n(t)+J(t)r(t)=s(t)+n(t)+J(t) 其中s(t)s(t)是传输的扩频调制信号。 当接收机达到同步要求时,其本地扩频序列与发射机扩频序列相同。 解扩也是以乘法器完成的,因此解扩输出信号m(t)m(t)为 m(t)===r(t)c(t)(s(t)+n(t)+J(t))c(t)a(t)c2(t)cos2πfct+n(t)c(t)+J(t)c(t)m(t)=r(t)c(t)=(s(t)+n(t)+J(t))c(t)=a(t)c2(t)cos2πfct+n(t)c(t)+J(t)c(t) 由于扩频序列c(t)c(t)取值为±1±1,故c2(t)=1c2(t)=1,且扩频序列c(t)c(t)与噪声和干扰n(t)n(t)、J(t)J(t)是不相关的,因此解扩输出的信号分量成为窄带信号,而噪声和干扰部分则是宽带的,即 m(t)=a(t)c


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 系统 仿真
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 广东省普通高中学业水平考试数学科考试大纲Word文档下载推荐.docx
广东省普通高中学业水平考试数学科考试大纲Word文档下载推荐.docx
-
计算题测试文档格式.docx
-
会计年终总结范文精选10篇Word文件下载.docx
-
基坑支护及降排水方案Word格式文档下载.docx
-
古代诗歌鉴赏一剪梅学案Word文档格式.docx
-
国标舞考级Word文件下载.docx
-
机电工程质量验收规范是什么Word文档下载推荐.docx
-
技术员工作自我评价文档格式.docx
-
交警支队车棚改造工程施工合同文档格式.docx
-
护士变更注册申请审核表与示范文本Word文档下载推荐.docx
-
最新学校新冠肺炎疫情防控应急预案Word文件下载.docx
-
GB50204钢筋规范之欧阳总创编Word格式文档下载.docx
-
《半期整改措施》Word格式.docx
-
诊断 症状学腰背痛关节痛汇总.docx
-
英美文学欣赏The Analysis of Shelleys Ode to the West Wind.docx
-
增值税营改增所得税消费税车购税测试题.docx
-
整理二级建造师管理真题.docx
-
英语三级重点高频词汇导入背单词APP使用.docx
-
浙教版学年九年级数学上册第2章测试题及答案.docx
-
证件照教学设计方案.docx
-
优品课件之《从锁国走向开国的日本》教案.docx
-
整理北京交通大学万用表组装实验报告.docx
-
质量管理计划.docx
-
有机化学鉴别.docx
-
整理照明灯饰灯具行业分类英语词汇.docx
-
濉溪县城市总体规划公示.docx
-
智能化工程质量验收记录表.docx
-
学生会纪检部工作总结.docx
-
幼儿园保教主任发言稿.docx
-
跆拳道协会工作总结.docx
-
中国茶叶店连锁市场竞争分析与竞争战略研究报告.docx
-
学宪法讲宪法主题演讲稿800字精选5篇弘扬宪法精神演讲稿5篇.docx
-
增广贤文原文注释.docx
-
外贸新人年终总结.docx
-
世界各大洲国家中英文名称列表.docx
-
精选说课稿九篇.docx
-
完整word版4开工企业应急预案2.docx
-
市场营销教案.docx
-
完整word版人教版小学五年级数学解决问题汇总.docx
-
精选团支部工作计划范文汇总六篇.docx
-
完整word版原土夯实施工方案.docx
-
精选销售工作总结模板集锦九篇.docx
-
护士长个人工作总结模板锦集9篇.docx
-
中国的能源状况与政策.docx
-
小学生趣味运动会活动方案.docx
-
七年级历史与社会暑假作业答案Word版.docx
-
水泵与水泵站的设计说明.docx
-
小学数学二年级口算.docx
-
七年级数学下册 春季课程 第六讲 坐标方法的简单应用试题新版新人教版.docx
-
中国农行河北分行校园招聘考试复习资料.docx
-
精选新年计划集锦六篇.docx
