 Lucene搜索入门教程Word文件下载.docx
Lucene搜索入门教程Word文件下载.docx
- 文档编号:15240654
- 上传时间:2022-10-28
- 格式:DOCX
- 页数:23
- 大小:1.83MB
Lucene搜索入门教程Word文件下载.docx
《Lucene搜索入门教程Word文件下载.docx》由会员分享,可在线阅读,更多相关《Lucene搜索入门教程Word文件下载.docx(23页珍藏版)》请在冰豆网上搜索。
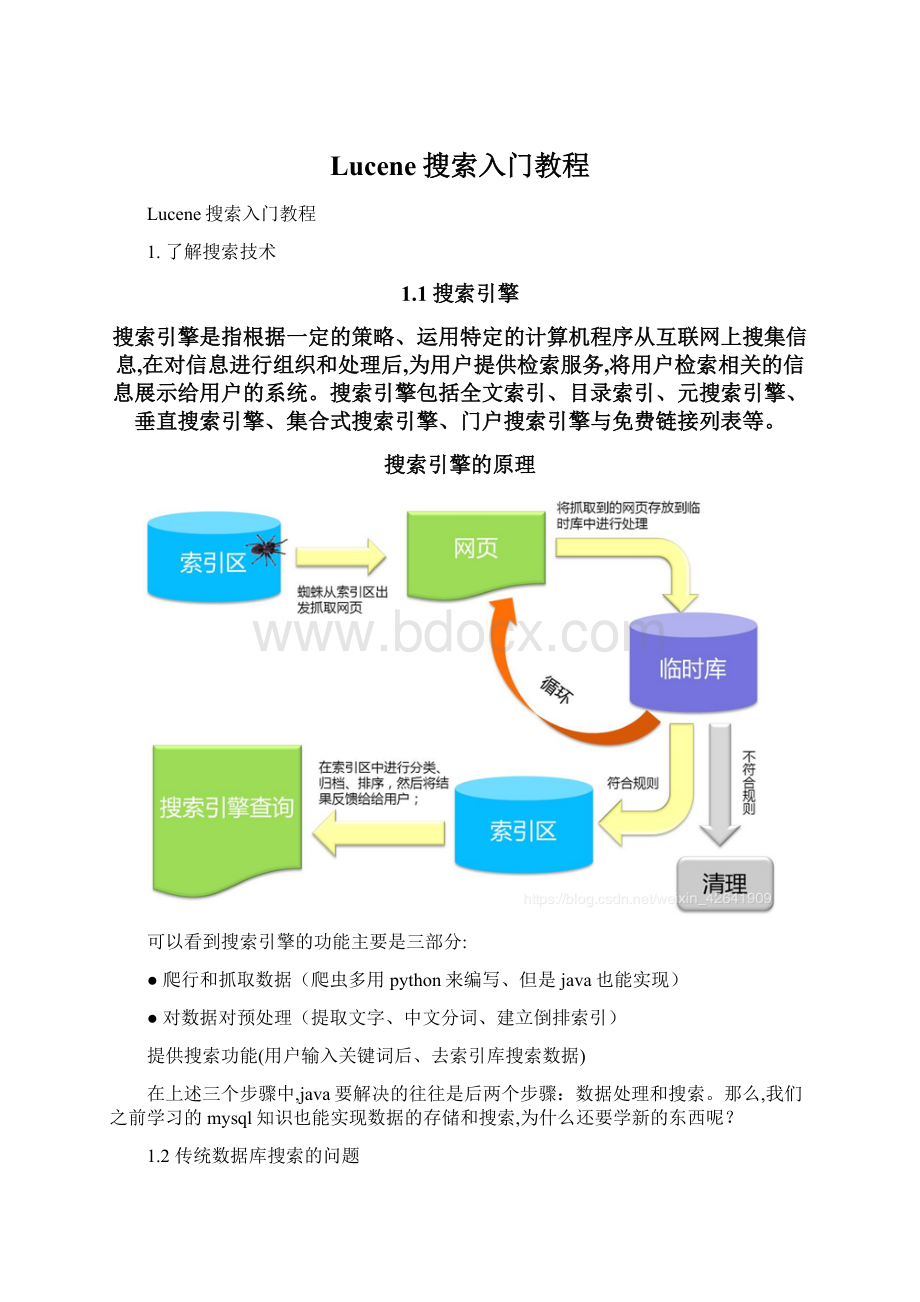
那么问题来了:
如何才能提高模糊搜索时的效率呢?
答案是:
倒排索引技术
1.3什么是倒排索引
倒排索引是一种存储数据的方式,与传统查找有很大区别:
●传统查找:
采用数据按行存储,查找时逐行扫描,或者根据索引查找,然后匹配搜索条件,效率较差.概括来讲是先找到文档,然后看是否匹配.
传统线性查找一个10MB的word文件,查找关键字如果在文档最后,大约3秒钟
●倒排索引:
首先对文档数据按照id进行索引存储,然后对文档中的数据分词,记录对词条进行索引,并记录词条在文档中出现的位置。
这样查找时只要找到了词条,就找到了对应的文档。
概括来讲是先找到词条,然后看看哪些文档包含这些词条。
它记录每个词条出现在哪些文档,及文档中的位置,可以根据词条快速定位到包含这个词条的文档及出现的位置
✓文档:
索引库中的每一条原始数据,例如一个网页信息,一件商品信息
✓词条:
原始数据按照算法进行分词,得到的每一个词
例如数据库中有这样一批数据:
1.3.1创建倒排索引流程
当我们需要把这些数据创建倒排索引时,会分为两步:
1)创建文档列表
首先给每一条原始的文档数据创建文档编号(docID),创建索引,形成文档列表:
2)创建倒排索引列表
然后对文档中的数据进行分词,得到词条。
对词条进行编号,并以词条创建索引。
然后记录下包含该词条的所有文档编号(及其它信息)。
1.3.2搜索流程
搜索的基本流程:
当用户输入任意的内容时,首先对用户输入的内容进行分词,得到用户要搜索的所有词条
然后拿着这些词条去倒排索引列表中进行匹配。
找到这些词条就能找到包含这些词条的所有文档的编号。
然后根据这些编号去文档列表中找到文档
举例:
例如用户要搜索关键词:
拉斯跳槽
●首先对这句话进行分词,得到2个词条:
拉斯、跳槽
●然后去倒排索引列表搜索(有索引,速度快),得到三个词所在的文档编号:
0、2、3、4
●然后根据编号到文档列表查找(有索引,速度快),即可得到原始文档信息了。
2.Lucene概述
2.1什么是Lucene
在java语言中,对倒排索引的实现中最广为人知的就是Lucene了,目前主流的java搜索框架都是依赖Lucene来实现的。
●Lucene是一套用于全文检索和搜寻的开源数据库,由Apache软件基金会支持和提供
●Lucene提供了一个简单却强大的应用程序接口(API),能够做全文索引和搜寻,在java开发环境里Lucene是一个成熟的免费开放源代码工具
●Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品
●官网:
http:
//lucene.apache.org/
什么是全文检索?
这里有一个陌生的词语:
全文检索。
其实全文检索就是利用倒排索引技术对需要搜索的数据进行处理,然后提供快速的全文匹配的技术。
2.2Lucene版本
●目前最新的版本是8.X系列,但是大多数企业中依旧使用4.X版本,比较稳定。
本次课程我们使用4.10.2版本,老版本下载地址:
//archive.apache.org/dist/lucene/java/
3.Lucene的基本使用
下面我们来看下Lucene对于索引的增(创建索引)、删(删除索引)、改(修改索引)、查(搜索数据)。
3.1创建索引
3.1.1基本流程:
流程:
●准备要添加的文档数据:
Document
●初始化索引写出工具:
IndexWriter
●设定索引存储目录Directory
●设定其他配置:
IndexWriterConfig
●设定分词器:
Analyzer
●设定Lucene版本
●写出索引
3.1.2添加依赖
3.1.3代码实现
查看目标目录:
3.1.4.索引查看工具
在课前资料中有工具,帮我们查看生成的索引:
双击run.bat即可运行,需要填写索引所在目录
首页:
可以看到分词的方式不太正确,一个字作为一个词,这是分词方式的问题,我们后续会解决。
文档信息:
3.2创建索引时的细节
创建索引的API有一些细节需要我们注意。
3.2.1覆盖或追加
我们在写索引时,可以在IndexConfigWriter中配置写入模式:
覆盖或者追加:
可以有3种模式:
●CREATE:
每次写入都覆盖以前的数据
●APPEND:
不覆盖数据,而是使用以前的索引数据后追加
●CREATE_OR_APPEND:
如果不存在则创建新的,如果存在则追加数据
3.2.2Field字段类型
刚才创建document的时候,我们添加了两个字段,StringField和TextField,其实Field还有很多其它实现类:
他们有一些不同的特性:
●DoubleField、FloatField、intField、LongField、StringField、TextField这些子类创建的字段一定会被创建索引。
但是不一定会被存储到文档列表.要通过构造函数中的参数Store来指定:
●Store.YES代表存储,在搜索结果中也会展示出来
●Stoe.NO代表不存储,在搜索结果中无法展示
这些字段虽然会创建索引,但是不一定会分词。
不分词的字段,会作为一个整体词条存入索引。
●TextField即创建索引,又会被分词。
其它Field会创建索引,但是不会被分词。
如果不分词,会造成整个字段作为一个词条,除非用户完全匹配,否则搜索不到:
我们一般,需要搜索的字段,都会被分词:
●上述所有字段都会创建索引,有一个外:
StoreField一定会被存储,但是一定不创建索引StoredField可以创建各种数据类型的字段:
一般,一些不需要进行搜索的字段我们无需创建索引,就可以使用StoreField类型
到底该使用哪个字段?
我们需要思考下面的问题:
●问题1:
这个字段是否需要创建索引?
●如果需要根据这个字段搜索,则这个字段需要创建索引。
●无需创建索引:
使用StoreField类型
使用除了StoreField外的其它类型
●问题2:
这个字段是否需要存储?
●如果一个字段要显示到最终的结果中,那么一定要存储,否则就不存储
●存储,则使用StoreField或者其它类型字段,但是构造函数第三个参数必须是Store.YES
●不存储,必须使用StoreField以外的字段,并且构造函数第三个参数必须是Store.NO
●问题3:
这个字段是否需要分词?
●这个字段首先要需要被搜索,因此剔除了StoreField.然后如果这个字段的值是不可分割的,那么就不需要分词,例如:
ID;
否则就需要分词
●需要分词:
使用TextField
●不需要分词:
使用除TextField外的其它几个类型
其实,这里最关键的是弄清楚一个字段:
是否需要存储、是否需要索引、是否需要分词。
弄清楚这个,就能知道怎么选择API了。
3.2.3分词器
刚才的案例中,我们使用了StandardAnalyzer分词器,不过这个分词器对中文的解析能力很差。
我们需要使用中文分词器。
一些比较流行的中文分词器:
这里我们使用IK分词器。
3.2.3.1Lk分词器
Lk分词器官方版本是不支持Lucene4.X的,有人基于lk的源码做了改造,支持了Lucene4.x,我们可以通过maven引入其依赖:
<
dependency>
<
groupId>
com.janeluo<
/groupId>
artifactId>
ikanalyzer<
/artifactId>
version>
2012_u6<
/version>
/dependency>
然后修改代码中的分词器类型:
再次测试:
3.2.3.2停用词典和扩展词典
IK分词器的词库有限,如果是词库中没有出现的词条,不会被正确分词,例如这样一句话:
谷歌地图之父跳槽facebook,加盟啊策策大数据技术社区,屌爆了啊
分词结果:
如图:
红色的词条是没有正确分词的;
蓝色的词条是没有意义的词语。
我们期待:
传智、屌爆了能作为一个完整词条;
并且一些无关词语如:
了、啊、额、入了可以不被分词。
新增加的词条可以通过配置文件添加到IK的词库中,也可以把一些不用的词条去除。
首先,我们需要在配置文件目录新建一个文件,编写扩展词条和停用词条:
●然后,在classpath下创建一个配置文件,名为:
IKAnalyzer.cfg.xml,把刚刚填写的词典配置进去:
结构:
再次测试后,查看结果:
3.2.4.批量创建索引
我们刚才使用IndexWriter中的addDocument方法来添加文档,然后写出到索引库,是一次添加一个文档。
事实上这里也支持批量添加:
可以看到这个API接收的是一个Interable类型,即迭代器类型,完全可以接收一个集合:
3.3.索引的基本查询
基本流程:
∙创建索引搜索工具
∙指定索引目录
∙创建读取流工具
∙创建搜索工具
∙创建查询条件
∙创建查询解析器
∙解析用户搜索语句,得到查询条件对象
∙搜索并解析结果
∙先到倒排索引列表获取文档编号集合
∙根据文档编号获取对应文档
代码如下:
结果:
拓展:
得分的基本规则:
1.越多罕见的词项被匹配上,文档的得分越高
2.文档字段越短(包含更少的词项),文档得分越高
3.权重越高(不论是索引期还是查询器赋予的权重值),文档得分越高
3.4.索引的高级查询
在刚才的基本查询中,我们使用QueryParser来解析并获取查询条件对象Query。
事实上,Query有很多的子类,代表各种不同的特殊查询方式:
我们创建不同的Query子类,就会实现不同的查询功能。
3.4.1抽取通用查询方法
当我们使用各种不同查询时,其它代码几乎不动,就是查询条件在发生变化,因此我们可以把查询代码进行抽取:
选中代码后按Ctrl+Alt+m
改造之前的查询:
3.4.2词条查询
词条,英文是Term,代表对原始数据进行分词后得到的每一个词语。
是搜索匹配时的最小单位,不可再分词。
因此词条查询


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- Lucene 搜索 入门教程
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 12处方点评管理规范实施细则_精品文档.doc
12处方点评管理规范实施细则_精品文档.doc
-
12核心制度竞赛题库_精品文档.doc
-
12新医疗技术准入制度_精品文档.docx
-
12月份医务科质控通报_精品文档.doc
-
12项基本公共卫生服务项目_精品文档.docx
-
12月环境卫生学监测方法考核试题_精品文档.doc
-
13双重预防体系风险评价制度及准则_精品文档.doc
-
12种不能忽视的可能的心脏病症状_精品文档.doc
-
13检验科“三基”考试试卷_精品文档.doc
-
14以预防为先导_精品文档.doc
-
12高危药品分级管理制度及目录_精品文档.doc
-
13个病种中医护理方案_精品文档.docx
-
16检验科应对突发事件应急预案_精品文档.docx
-
12急救药品管理制度_精品文档.doc
 17种抗癌药纳入国家基本医疗保险工伤保险和生育保险药品目录_精品文档.xls
17种抗癌药纳入国家基本医疗保险工伤保险和生育保险药品目录_精品文档.xls
-
14医疗器械召回程序_精品文档.wps
-
13医用耗材库房管理制度_精品文档.doc
-
136个幼儿园英语课堂游戏_精品文档.docx
-
12经络彩图_精品文档.doc
-
151颅脑损伤恢复期康复临床路径_精品文档.doc
-
14项护理核心制度_精品文档.doc
-
12检验科化学危险物品使用准则_精品文档.doc
-
15-消化内镜手术分级目录_精品文档.xls
-
13术前讨论记录本模板_精品文档.doc
-
17-下腰痛评估表JOAVAPS_精品文档.doc
-
12项基本公共卫生服务流程图_精品文档.doc
-
13中国髋膝关节置换的现状及展望_精品文档.docx
-
14种最迷惑人的癌症前兆_精品文档.docx
-
17消毒供应室医院感染管理制度_精品文档.doc
-
15附加住院津贴保险条款的费率-人保财险备-健康附号_精品文档.doc
-
19陕西省崔家沟监狱罪犯医疗防疫总站突发事件预案_精品文档.doc
-
20项护理技术操作规程及评分标准_精品文档.doc
-
《国家住宅设计规范》.docx
-
《信息化项目管理制度》.docx
-
20xx年大学生物流企业实习报告5篇.docx
-
1施工组织总体设想方案针对性及施工标段划分86210.docx
-
100道100以内的加减法口算练习题.docx
-
7S现场管理奖惩实施方案doc.docx
-
0831单梁桥式起重机质量证明书.docx
-
32位PowerPC常用指令集总结.docx
-
《电力用户业扩工程技术规范》.docx
-
《基于网络环境培养小学生信息素养的研究》课题开题报告范文.docx
-
《信息安全等级测评师培训教程初级》学习笔记.docx
-
26年社会学概论真题有答案.docx
-
《麻雀》教案.docx
-
3套精选人教版七年级下册第五章《相交线与平行线》测试题解析版1.docx
-
11与朱元思书.docx
-
40米架桥机详细计算书.docx
-
《超过一定规模的危险性较大的分部分项工程安全管理办法》资料.docx
-
《皇帝的财宝》全攻略.docx
-
《理想国》中对美和善的论述美学论文哲学论文.docx
