 Oracleotd学习.docx
Oracleotd学习.docx
- 文档编号:30479901
- 上传时间:2023-08-15
- 格式:DOCX
- 页数:16
- 大小:412.08KB
Oracleotd学习.docx
《Oracleotd学习.docx》由会员分享,可在线阅读,更多相关《Oracleotd学习.docx(16页珍藏版)》请在冰豆网上搜索。
Oracleotd学习
第9讲伪列
1.伪列概念
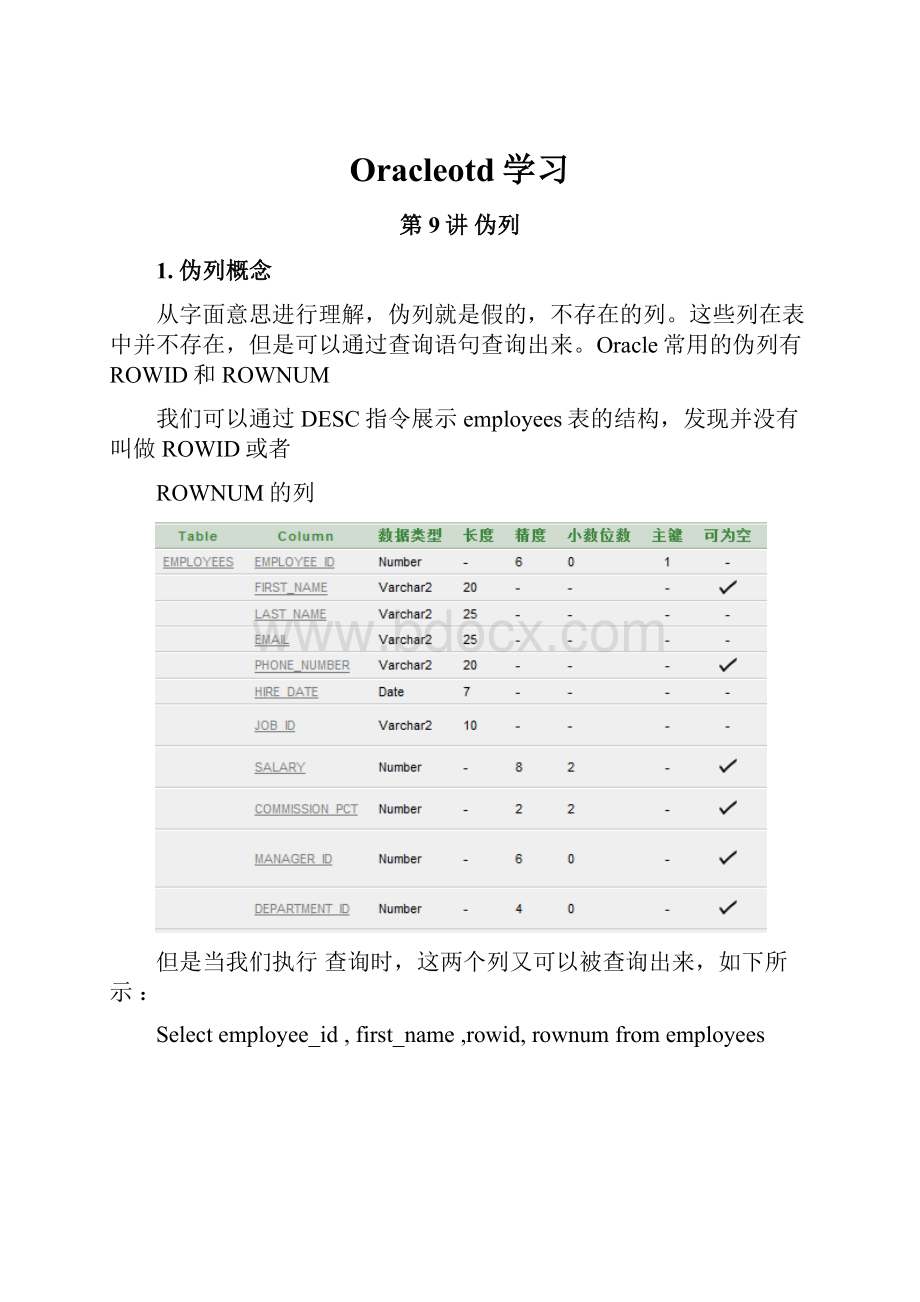
从字面意思进行理解,伪列就是假的,不存在的列。
这些列在表中并不存在,但是可以通过查询语句查询出来。
Oracle常用的伪列有ROWID和ROWNUM
我们可以通过DESC指令展示employees表的结构,发现并没有叫做ROWID或者
ROWNUM的列
但是当我们执行查询时,这两个列又可以被查询出来,如下所示:
Selectemployee_id,first_name,rowid,rownumfromemployees
这两个列就是我们所说的伪列。
接下来我们来介绍一下这两个列的作用。
2.ROWID伪列
Rowid伪列能够在数据库中唯一标示一条记录。
他的运算方法很复杂,是根据数据在硬
盘上的存储位置(扇区,磁道)运算得出的。
由于条数据在硬盘中的存储位置都是独一无二的,所以通过rowid能够在整个数据库范围内唯一标识一条数据。
又因为rowid中包含数据在磁盘上的存储地址。
所以通过rowid查询对应的数据效率是最高的。
但是由于rowid没有任何含义,所以以rowid作为条件的查询并不常用。
3.ROWNUM伪列
通过前面关于rownum的查询可以看出,rownum的功能实际上是给给查询结果一个编号,第一个满足查询条件的数据,对应的rownum是1,第二个满足查询条件的数据rownum是2,如果有更多满足查询条件的数据,rownum依次递增。
这条数据满足where条件的先后顺序
利用rownum,我们可以实现很多实用的查询.比如,我们想查询公司的全前5名员工,就可以通过rownum<=5来进行判断。
Select*fromemployeeswhererownum<=5;
接下来,我们再讨论一下能否使用rownum查询到第5个员工之后的员工,即:
select*fromemployeeswhererownum>5
通过实验我们发现这条查询实际得不到任何结果。
原因在于rownum代表的是查询结果的编号,第一个满足查询的数据的rownum是1,第二个满足查询条件的数据rownum为2,也就是说rownum必须从1开始产生,而我们的查询条件rownum>5,是永远不会被满足的。
大家可以通过参考下面的图进一步理解这个问题。
拿到第一条记录,rownum赋值为1,跟5进行比较,条件不符;
取下一条记录,同样rownum赋值为1,跟5进行比较,条件不符…
由此我们可以总结这样一个规律:
rownum用作条件比较时,只能用于<,<=,=1,>=1条件
●ROWNUM与ORDERBY联合使用
我们来看这样一个问题查询工资最高的前5名员工.很多同学会立刻想到用这样的sql来解决:
select*fromemployeeswhererownum<=5orderbysalarydesc,我们来看一下查询结果:
但是细心的同学会发现这个查询结果并不正确,大家可以参考下面的实际数据进行对比
Select*fromemployeesorderbysalarydesc
我们会发现被查询出来的并不是工资最高的钱五个人。
这是什么原因造成的呢?
这是因为orderby子句是在查询完成之后执行的。
Rownum是在查询进行的过程中就产生的,上面的SQL实际上做的事请是,查出前五个员工,然后对这五个员工的工资进行排序,而不是查询全公司工资最高的前五人。
如何解决此问题呢?
这就需要使用到下一讲的内容:
子查询
第10讲子查询
首先我们通过一个例子来了解什么是子查询。
我们要将公司中工资最高的人的姓名,工资和电话查询出来。
我们首先想到的方式是:
Selectfirst_name,last_name,phone_number,salary
Fromemployees
Wheresalary=max(salary);
但是这条SQL在编译时会出现语法错误,原因也很简单,我们在上一讲中强调过,where语句是在分组之前执行的,在没有分组之前,max(salary)是无法获得的。
所以在where语句中无法直接使用组函数(count,max,min,sum,avg)作为查询条件。
所以我们只能把上述查询要求分成两个查询操作来完成:
1,查出公司的最高工资是多少。
2,以最高工资为条件,查询员工姓名等信息。
selectmax(salary)fromemployees
selectfirst_name,phone_number,salaryfromemployeeswheresalary=24000
在数据库操作中,我们期望使用最少的SQL语句完成查询要求,这样可以提高执行效率,也会使代码更加简洁。
利用子查询,可以将上面两个查询语句,合并成一条查询语句:
select
first_name,phone_number,salary
from
employees
where
salary=(selectmax(salary)fromemployees)
程序的执行结果完全一致。
在上面的例子中,我们把selectmax(salary)fromemployees的查询结果直接参与到了where条件的比较中,因此我们把这条查询语句称作子查询。
1.子查询返回结果:
(1)一个值
(2)临时表
1)查询的结果如果是一行一列,可以将结果看做一个值,参与条件比较或显示在SELECT子句。
2)查询的结果如果是多列,可以将结果看做一个临时表,可以针对此临时表进行再次查询、分组、排序、表连接等各种操作
2.将子查询看做是一个值
在前面查询工资最高的员工例子中,我们已经看到了这种子查询的用法,需要注意的是对于主查询的每一行都会运行子查询,回忆一下我们前面讲过的where的执行特点,表中的每条数据都会参与where运算,来决定这条数据是否满足查询条件。
所以where条件是要重复执行的。
那么子查询是where子句的一部分,每次where语句执行的时候,子查询都会被执行一次。
我们再来通过一个例子了解一下单值子查询的用法,查询工资低于公司平均工资的员工信息.
select
first_name,phone_number,salary
from
employees
where
salary<(selectavg(salary)fromemployees)
部分运行结果为:
接下来,我们再来看一个子查询的例子:
查询每个部门具有最高工资的员工信息
select*fromemployeese1
wheree1.salary=
(
selectmax(e2.salary)fromemployeese2
wheree2.department_id=e1.department_id
)
运行结果如下:
在上面的例子中,我们将在子查询中使用了外层查询的类作为where条件,
(wheree2.department_id=e1.department_id)这种用法看起来有些复杂,实际上,我们只要理解了子查询的执行策略就容易解释这个问题了。
在前面我们介绍过,employees表中的每条数据都要进行where运算,也就是说针对employees表中的每条数据,都会进行一次子查询。
在每次子查询运行的过程中,外层查询的department_id(e1.department_id)都是一个固定值:
比如,当前where条件是对101号员工进行判断,那么e1.department_id就等于90(在employees表中,101员工的部门号为90),子查询代码就变成:
selectmax(e2.salary)fromemployeese2wheree2.department_id=90
当where条件对103号员工进行判断时,子查询语句就变成:
selectmax(e2.salary)fromemployeese2wheree2.department_id=60
当where条件对108号员工进行判断时,子查询语句变成
selectmax(e2.salary)fromemployeese2wheree2.department_id=100
这样我们可以保证,每次与员工与员工工资进行比较的都是该员工所在部门的最高工资。
需要特殊说明的是在上例中,我们为了区分外层查询和子查询,我们为employees表取了两个别名,分别是e1和e2,这样做的目的是为了区分e1.department_id=e2.department_id。
为表取别名不能使用”AS”。
大家可以自己思考一个问题:
使用本题的思路实现显示员工信息的同时,显示他所在部门的最高工资
3.将子查询看做一个临时表
我们来回忆一下以前遇到的一个问题,查询工资最高的前5名员工,当时我们的sql语句是这样写的:
select*fromemployeeswhererownum<=5orderbysalary,通过观察查询结果我们发现,这条SQL查询的数据是错误的,因为排序是发生在查询之后的,所以上面的SQL语句只是对前五个员工的工资进行了排序,并不是对所有员工的工资进行排序。
现在可以通过子查询来间接解决这个问题。
我们的思路是:
先利用子查询将所有员工按照工资排序,将排序后的查询结果看成一张临时表临时表,再对此临时表进行查询,使用ROWNUM限制返回行数
select*
from(
select*fromemployeesorderbysalarydesc
)
whererownum<=5;
查询结果为:
思考:
查询工资排在第6到第10之间的5位员工。
第11讲连接查询
在我们前面学习的查询技术中,有一个共同的特点,就是查询的数据都是来自同一张表。
在很多时候,我们需要同时查询多张表才能获取所需数据。
比如我们熟悉的employee表中,保存了每个员工的部门ID号,而部门的详细信息,如部门名称,则保存在departments表里,如果我们现在需要查询每个员工的个人信息,以及所属部门名字的话,就需要同时查询employees表和departments表,这时就需要用到连接查询技术。
Employees表和departments表的表结构以及部分数据如下图所示:
Employees表的部分数据:
Departments表的部分数据:
1.内连接
内连接是最容易理解的一种表连接技术,我们以employees表和departments表为例来了解一下内连接的工作原理。
从两个表的结构中我们可以看出,两张表中的数据是通过employees表的departments_id和departments表中的departments_id关联起来的。
如果我们想找到一个员工的部门名称的话,就要现在employees表中找出该员工的departments_id的值,比如这个值是10,然后,再到departments表中找到department_id等于10的部门数据,从而得到部门的名称。
这个过程其实就是一个简单的内连接过程,这个过程中有一个很重要的因素,就是只有在employees表的department_id和departments表中的department_id相等的时候,来自两个表的数据才会连接成功,在数据库专用术语中,就把employees.department_id=departments.department_id称作连接条件。
所谓的内连接,其实就是先确定A,B两个表的连接条件,然后拿A表里面的每一条数据与B表中的所有数据依次比较,判断连接条件是否成立,如果连接条件成立,则将来自两个表中的两条数据合二为一,保存到结果集中。
如果条件不成立,就继续和B表中的下一条数据进行比较。
如果A表中的一条数据在整个B表里都无法找到一条与之对应的记录,那么这条数据就不会出现在查询结果中了。
最终,结果集中保存的都是连接条件成立的数据。
我们通过下图来理解一下内连接的工作过程.
Employees表departments表
连接过程示意图
了解了内连接的工作原理之后,我们来学习一下内连接的SQL语法
select
e.*,d.*
from
employeeseinnerjoindepartmentsd
one.department_id=d.department_id
其中e.*和d.*分别表示employees中的所有列和departments表中的所有列。
e和d分别是employees和departments的别名,innerjoin(也可以简写为join)表示要对左右两个表进行内连接操作,one.department_id=d.department_id用于指定连接条件。
以下是上述SQL的部分查询结果:
在使用内连接的时候要特别注意两点,
1,必须指定正确的连接条件
2,只有符合连接条件的数据才能出现在查询结果中。
我们可以通过实验检查一下,在上面的查询中有很多部门没有出现在查询结果中,比如210号部门,原因是,在employees表里,没有任何员工隶属于210号部门。
这样210号部门永远无法满足查询条件,在结果中自然不包括到它。
2.外连接
上两表做连接时210号部门没有出现在查询结果中,如果希望210号部门信息也能够被查询出来怎么办呢?
我们可以通过左外连接解决,外连接的SQL语法为leftjoin,他可以将连接符号左侧表中的数据全部查询出来,包括没能在右侧表中找到对应数据的记录。
selecte1.employee_id,e1.first_name,e1.manager_id,e2.first_nameasmanager_name
fromemployeese1rightjoinemployeese2one1.manager_id=e2.employee_id
selecte1.*,e2.first_nameasmanager_name
fromemployeese1leftjoinemployeese2one1.manager_id=e2.employee_id
selecte1.*,d.department_idasmanager_name
fromemployeese1leftjoindepartmentsdone1.manager_id=d.DEPARTMENT_ID
3.自连接
在进行连接查询的时候,有时候需要用一个表自己连接自己,比如我们想查询员工信息以及其上级的编号和姓名。
这时我们就将employees表当做两张表来看待就可以了,为了表示区别,可以为employees取两个别名e1和e2。
selecte1.employee_id,e1.first_name,e1.manager_id,e2.first_nameasmanager_name
fromemployeese1joinemployeese2one1.manager_id=e2.employee_id
课堂练习:
查询员工及其下属的编号和姓名
4.笛卡尔连接
如果我们再进行内连接或者外连接的时候,忘记指定连接条件的话,那么所有的数据都会被纳入到查询结果中,如果A表有10条数据,B表有4条数据的话,最终的结果中就会出现10*4条数据。
这种形式称作笛卡尔乘积。
如果A,B表中的数据较多的话,会造成查询结果异常庞大,而且,通过笛卡尔乘积连接起来的数据没有实际意义,所以我们在使用连接查询时,要尽量避免这种情况的出现。
5.不等值连接
所谓不等值连接,就是指连接条件不是通过等于运算符进行运算的。
比如:
有一张工资级别表,存储了工资级别的信息,由losal(本级别工资最低值),hisal(本级别工资最高值),y以及级别名称三列组成。
查询每个员工的信息及其工资级别
selecte.*,gradefromemployeeeinnerjoinsalgradeson(e.salbetweens.losalands.hisal);
6.多表连接
当参与连接的表超过2张表以上时,我们就称这个链接为多表连接。
比如我们要查询员工信息,以及部门名称,和部门所在地。
员工信息存储在employees表中,部门名称存储在department表中,部门所在地信息存储在locations表中,这是就需要将三张表连接到一起了。
在使用多表连接时,可以将前两个表的连接结果看成一张临时表,再于第三个表进行连接.


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- Oracleotd 学习
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《贝的故事》教案4.docx
《贝的故事》教案4.docx
-
《对韵歌》优秀教案8.docx
-
《函数yAsinωx+φ+P图象》wwwnet.docx
-
《静夜思》教学设计.docx
-
《汽车底盘构造与维修》题库与考核标准.docx
-
《世说新语》复习资料.docx
-
《我的服装我做主》教案设计.docx
-
《在品味情感中成长》教学片断设计.docx
-
11造价员《建设工程造价管理基础知识》精讲教程文件.docx
-
《不会叫的狗》教案 人教部编版1.docx
-
《操作系统》二学期A卷及答案.docx
-
《傅雷家书》名著阅读笔记.docx
-
《反不正当竞争法》下互联网平台封禁行为考辨以消费者用户合法权益保护为中心.docx
-
《化工原理》第六章蒸发.docx
-
《蓝海战略》概要11页.docx
-
《人生》读书心得.docx
-
《荷叶圆圆》公开课教案优秀教学设计26.docx
-
《科技出行研究报告》智能网联与新能源将变革未来汽车出行.docx
-
《272 向量的应用举例》导学案1.docx
-
《秋天》评课稿.docx
-
《电算化》第二章会计电算化的工作环境章节练习.docx
-
《室外给排水管道》施组.docx
-
《广东省建筑与装饰工程综合定额》计算规则.docx
-
《我多想去看看》教学.docx
-
《直通车车手基础认证》 考试答案 70题之欧阳育创编.docx
-
7天销量翻10倍皇冠卖家教您玩转最精准流量.docx
-
9 阿长和山海经.docx
-
《比例尺》教案.docx
-
《菜根谭》注译四闲适篇.docx
-
《福尔摩斯探案集》读后感15篇.docx
-
《红对勾》古代诗歌选择题答案补充.docx
-
《课堂密码》读后感及心得精选多篇.docx
-
00156《成本会计》笔记Word下载.docx
-
秋七年级体育课教案秋期Word格式.docx
-
可行性分析说明书Word文件下载.docx
-
安全生产月演讲稿Word格式文档下载.docx
-
矿山救护仪器中普遍使用的化学药剂正式版Word文件下载.docx
-
安全教育培训计划内容docWord下载.docx
-
导师指导工作总结Word文件下载.docx
-
服装展现场管理计划Word下载.docx
-
路灯节能智能控制系统设计与研究Word格式.docx
-
道路施工工序流程Word文档下载推荐.docx
-
安全教育主题班会教案详细版Word文件下载.docx
-
爆破设计方案设计实用标准Word格式.docx
-
北京朝阳高三一模英语卷Word文档下载推荐.docx
-
安全生产管理台账范本全套Word格式文档下载.docx
-
《全统修缮土建工程陕西省价目表》使用说明.docx
-
sb安全生产工程质量贯标管理办法word资料119页Word格式.docx
-
统计法基础知识综合应用题Word文档下载推荐.docx
-
火锅店开业精彩活动方案设计Word文档下载推荐.docx
-
安全生产监督管理办法Word格式文档下载.docx
