 粒子滤波及matlab实现.docx
粒子滤波及matlab实现.docx
- 文档编号:28234038
- 上传时间:2023-07-09
- 格式:DOCX
- 页数:27
- 大小:231.88KB
粒子滤波及matlab实现.docx
《粒子滤波及matlab实现.docx》由会员分享,可在线阅读,更多相关《粒子滤波及matlab实现.docx(27页珍藏版)》请在冰豆网上搜索。
粒子滤波及matlab实现
粒子滤波及matIab实现
粒子滤波就是指:
通过寻找一组在状态空间中传播的随机样本来近似的表示概率密度函数,用样本均值代替积分运算,进而获得系统状态的最小方差估计的过程,这些样本被形象的称为“粒子”,故而叫粒子滤波。
粒子滤波通过非参数化的蒙特卡洛(MonteCarlo)模拟方法来实现递推贝叶斯滤波,适用于任何能用状态空间模型描述的非线性系统,精度可以逼近最优估计。
粒子滤波器具有简单、易于实现等特点,它为分析非线性动态系统提供了一种有效的解决方法,从而引起目标跟踪、信号处理以及自动控制等领域的广泛关注。
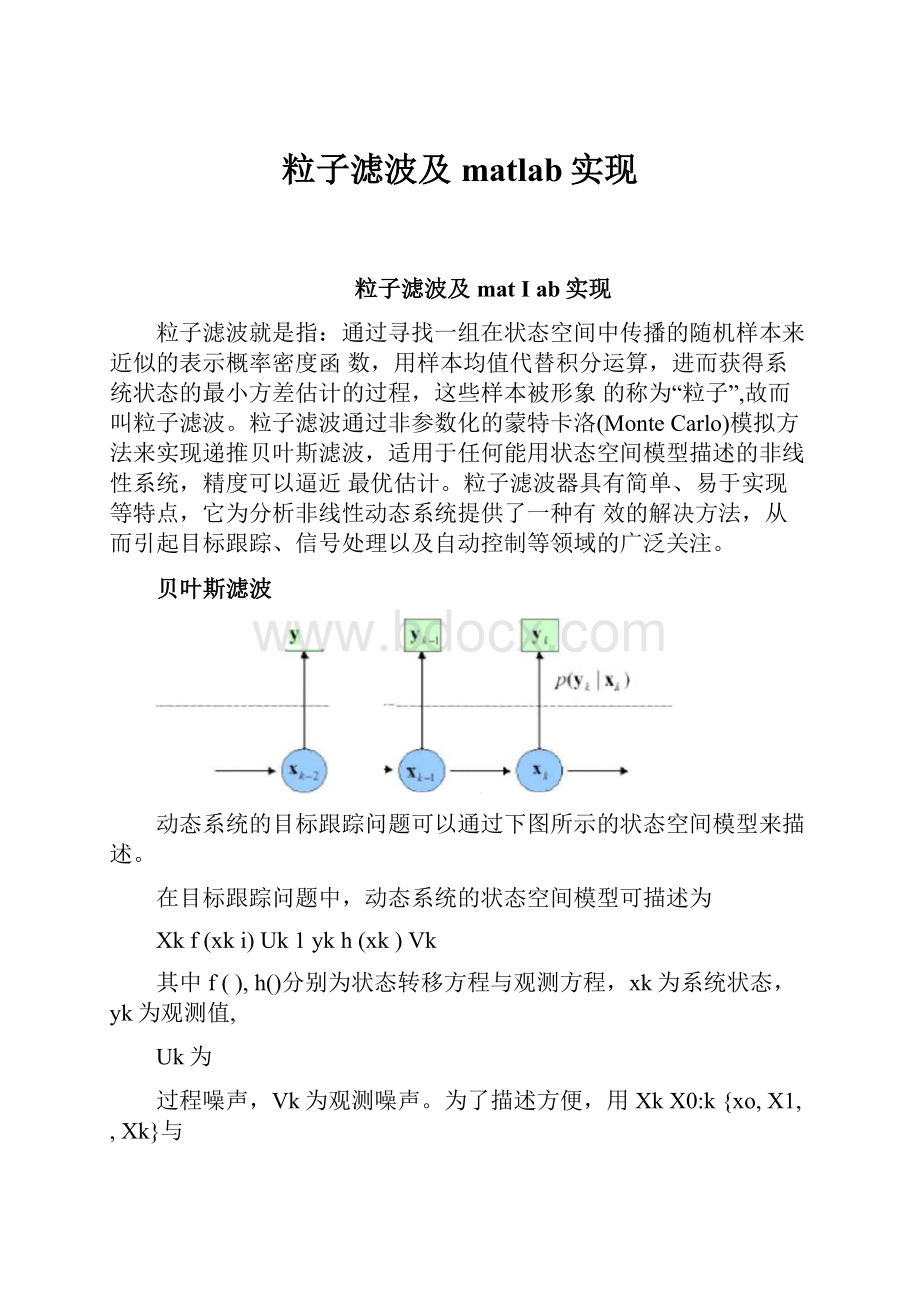
贝叶斯滤波
动态系统的目标跟踪问题可以通过下图所示的状态空间模型来描述。
在目标跟踪问题中,动态系统的状态空间模型可描述为
Xkf(xki)Uk1ykh(xk)Vk
其中f(),h()分别为状态转移方程与观测方程,xk为系统状态,yk为观测值,
Uk为
过程噪声,Vk为观测噪声。
为了描述方便,用XkX0:
k{xo,X1,,Xk}与
Vkyi:
k{yi,,yk}分别表示0到k时刻所有的状态与观测值。
在处理目标跟踪问题时,通
常假设目标的状态转移过程服从一阶马尔可夫模型,即当前时刻的状态Xk只与上一时刻的状态Xk-1有关。
另外一个假设为观测值相互独立,即观测值yk只与k时刻的状态Xk有关。
贝叶斯滤波为非线性系统的状态估计问题提供了一种基于概率分布形式的解决方案。
贝叶斯滤波将状态估计视为一个概率推理过程,即将目标状态的估计问题转换为利用贝叶斯公式求解后验概率密度p(Xk|Yk)或滤波概率密度p(xk|Yk),进而获得目标状态的最优估计。
贝叶
斯滤波包含预测和更新两个阶段,预测过程利用系统模型预测状态的先验概率密度,新过程则利用最新的测量值对先验概率密度进行修正,得到后验概率密度。
假设已知k1时刻的概率密度函数为p(xk1|Y-),贝叶斯滤波的具体过程如下:
(1)预测过程,由p(xk11Yk1)神p(xk|Yki)
p(Xk,Xk11Yki)p(xk|Xk1,Yki)p(xk11Yki)
当给定Xk1时,状态Xk与Yk1相互独立,因此
p(xk,Xk11Yki)p(xk|Xki)p(xki|Yki)
上式冷Xk1积分,可得Chapman-KomoIgorov方程
p(xk|Yki)p(xk|Xki)p(xk11Yki)dxk1
⑵更新过程,由p(xk|Yki)得到p(xk|Yk):
获取k时刻的测量yk后,利用贝叶斯公式对先验概率密度进行更新,得到后验概率
p(xk|Yk)
砲yu只由xk决定,即
P(yk|xk,Yki)
因此
P(xrIYk)
p(yk|Xk,Yki)p(xk|Yki)
P(yk|Yki)
P(yk|xk)
p(yk|Xk)p(xk|Yki)
P(yk|Yki)
其中,p(yk|Yki)为归一化常数
p(yk|Yki)p(yk|xk)p(xk|Yk1)dxk
贝叶斯滤波以递推的形式给出后验(或滤波)概率密度函数的最优解。
目标状态的最优估计值可由后验(或滤波)概率密度函数进行计算。
通常根据极大后验(MAP)准则或最小均方误差(MMSE)准则,将具有极大后验概率密度的状态或条件均值作为系统状态的估计值,即X?
k・二argminp(xk|Yk)x?
”…二E[f(xk)|Y订f(xk)p(xk|Yk)dxk
贝叶斯滤波需要进行积分运算,除了一些特殊的系统模型(如线性高斯系统,有限状态的离散系统)之外,对于一般的非线性、非高斯系统,贝叶斯滤波很难得到后验概率的封闭解析式。
因此,现有的非线性滤波器多采用近似的计算方法解决积分问题,以此来获取估计的次优解。
在系统的非线性模型可由在当前状态展开的线性模型有限近似的前提下,基于一阶或二阶Taylor级数展开的扩展Kalman滤波得到广泛应用。
在一般情况下,逼近概率密度函数比逼近非线性函数容易实现。
据此,Julier与Uhlmann提出一种UnscentedKaIman滤波器,通过选定的sigma点来精确估计随机变量经非线性变换后的均值和方差,从而更好的近似状态的概率密度函数,其理论估计精度优于扩展Kalman滤波。
获取次优解的另外一中方案便是基于蒙特卡洛模拟的粒子滤波器。
粒子滤波
早在20世纪50年代,Hammersley便采用基于序贯重要性采样(SequentialimportancesampIing,SIS)的蒙特卡洛方法解决统计学问题1,2,1o20世纪60年代后期,Handschin与Mayne使用序贯蒙特卡洛方法解决自动控制领域的相关问题。
20世纪70年代,Handschin、Akashi
以及Zaritskii等学者的一系列研究工作使得序贯蒙特卡洛方法得到进一步发展。
限于当时的计算能力以及算法本身存在的权值退化问题,序贯重要性采样算法没有受到足够重视,在随
后较长一段时间内进展较为缓慢。
直到20世纪80年代末,计算机处理能力的巨大进展使得
序贯蒙特卡洛方法重新受到关注。
Tanizaki、Geweke等采用基于重要性采样的蒙特卡洛方法
成功解决了一系列高维积分问题。
Smith与GeIfand提出的采样-重采样思想为Bayesian
推理提供了一种易于实现的计算策略。
随后,Smith与Gordon等人合作,于20世纪90年代初将重采样(Resampling)步骤引入到粒子滤波中,在一定程度上解决了序贯重要性采样的权值退化问题,并由此产生了第一个可实现的SIR(SampIingimportanceresampling)粒子滤波算法(Bootstrap滤波),从而掀起粒子滤波的研究热潮。
美国海军集成水下监控系统中的
Nodestar
便是粒子滤波应用的一个实例。
进入21世纪,粒子滤波器成为一个非常活跃的研究领域,
Doucet、Liu、Arulampalam等对粒子滤波的研究作了精彩的总结,IEEE出版的论文集
“SequentiaIMonteCarloMethodsinPractice对粒子滤波器”进行了详细介绍。
贝叶斯重要性采样
蒙特卡洛模拟是一种利用随机数求解物理和数学问题的计算方法,又称为计算机随机模拟方法。
该方法源于第一次世界大战期间美国研制原子弹的曼哈顿计划,著名数学家冯诺伊曼作为该计划的主持人之一,用驰名世界的赌城,摩纳哥的蒙特卡洛来命名这种方法。
蒙特卡洛模拟方法利用所求状态空间中大量的样本点来近似逼近待估计变量的后验概率分布,如图2.2所示,从而将积分问题转换为有限样本点的求和问题。
粒子滤波算法的核心思想便是利用一系列随机样本的加权和表示后验概率密度,通过求和来近似积分操作。
假设可以从后验概率密度p(xk|Yk)中抽取N个独立同分布的随机样本Xk(),i1,,N,则有
1K(i)
(0.1)
p(xk|Yk)n1i1(xkXk-)
^Xk为连续变量,(X-Xk)为单位冲激函数(狄拉克函数),即(X-Xk)0,XXk,且(x)dx1o当Xk为离散变量时,后验概率分布P(xk|Yk)可近似逼近为
图2.1经验概率分布函数
Fig・2.1EmpiricaIprobabiIitydistributionfunction
设Xk•为从后验概率密度函数p(xk|Yk)中获取的采样粒子,则任意函数f(Xk)的期望
估计可以用求和方式逼近,即
1N(.)
E[f(xk)|Yk]
f(xk)p(xk|Yk)dxk1f(xk⑴)(0.3)
Nii蒙特卡洛方法
一般可以归纳为以下三个步骤:
(1)构造概率模型。
对于本身具有随机性质的问题,主要工作是正确地描述和模拟这个概率过程。
对于确定性问题,比如计算定积分、求解线性方程组、偏微分方程等问题,采用蒙特卡洛方法求解需要事先构造一个人为的概率过程,将它的某些参量视为问题的解。
(2)从指定概率分布中采样。
产生服从己知概率分布的随机变量是实现蒙特卡洛方法模拟
试验的关键步骤。
(3)建立各种估计量的估计。
一般说来,构造出概率模型并能从中抽样后,便可进行现模
拟试验。
随后,就要确定一个随机变量,将其作为待求解问题的解进行估计。
在实际计算中,通常无法直接从后验概率分布中采样,如何得到服从后验概率分布的随机样本是蒙特卡洛方法中基本的问题之一。
重要性采样法引入一个已知的、容易采样的重要性概率密度函数q(xk|Yk),从中生成采样粒子,利用这些随机样本的加权和来逼近后验滤波概率密度p(Xk|Yk),如图2.3所示。
令{i1,・N}表示一支撑点集,
其中Xk⑴为是k时刻第i个粒子的状态,其相应的权值为,则后验滤波概率密度可以表示为
P(Xk|丫»wk-(xkxj)(0.4)
i1
其中,
图2.2a要性采样
Fig.2.2ImportancesampIing当采样粒子的
数目很大时,式(2.14)便可近似逼近真实的后验概率密度函数。
任意函数f(Xk)的期望估计为
1N
N1i1f(Xk“)Wk"(0.6)
川p(Xk-
E[f(xk)|Y订=Ji1|Yk)
序贯重要性采样算法
在基于重要性采样的蒙特卡洛模拟方法中,估计后验滤波概率需要利用所有的观测数据,每次新的观测数据来到都需要重新计算整个状态序列的重要性权值。
序贯重要性采样作为粒子滤波的基础,它将统计学中的序贯分析方法应用到的蒙特卡洛方法中,从而实现后验滤波概率密度的递推估计。
假设重要性概率密度函数q(xo:
k|yi:
k)可以分解为
q(xo:
k|yi:
k)q(xo:
k1|yi:
k1)q(Xk|xo:
k1,yi:
k)(0.7)
设系统状态是一个马尔可夫过程,且给定系统状态下各次观测独立,则有
k
p(xo:
k)p(xo)p(xi|Xi1)(0.8)
后验概率密度函数的递归形式可以表示为
p(xo:
k|Yk)
p(yk|xo:
k,Yki)p(xo:
k
|Yki)
p(yk|xo:
k,Yki)p(xk|xo:
k1,Yk
i)p(xo:
k11Yki)p(yk|Yki)
p(yk|Xk)p(xk|Xki)p(xo:
ki|Yki)p(yk|Yki)
粒子权值Wk”的递归形式可以表示为
i)P(xo:
k
|Yk)q(xo:
k
a
p(yk丨xQp(xk⑴|xk-Jp(x
I\
q(xi)|xo(:
kj1,Yk)q(x(r火11Yki)
p(ykI)p(xj|x宀)
/I11)
q(Xk⑴Ix°:
ki,Yk)
通常,需要对粒子权值进行归一化处理,即
序贯重要性采样算法从重要性概率密度函数中生成采样粒子,并随着测量值的依次到来递
推求得相应的权值,最终以粒子加权和的形式来描述后验滤波概率密度,进而得到状态估计。
序贯重要性采样算法的流程可以用如下伪代码描述:
[{Xk⑴,Wk<4i"i]SIS({xreWkh}山,Yk)
Fori=1:
N
⑴时间更新,根据重要性参考函数q(xf|x0:
vi,Yk)生成采样粒子xk-
(2)量测更新,根据最新观测值计算粒子权值Wk®;
EndFor
粒子权值归一化,并计算目标状态。
为了得到正确的状态估计,通常希望粒子权值的方差尽可能趋近于零。
然而,序贯蒙特卡洛模拟方法一般都存在权值退化问题。
在实际计算中,经过数次迭代,只有少数粒子的权值较大,其余粒子的权值可忽略不计。
粒子权值的方差随着时间增大,状态空间中的有效粒子数较少。
随着无效采样粒子数目的增加,使得大量的计算浪费在对估计后验滤波概率分布几乎不起作用的粒子更新上,使得估计性能下降。
通常采用有效粒子数Neff来衡量粒子权值的退化程度,即
NeffN/(1var(wv°))(0.13)
WW4「(\门Ji)]')(0.诫q(xkIXk1,yi:
k)
有效粒子数越小,表明权值退化越严重。
在实际计算中,有效粒子数Neff可以近似为
p.91
NeffN(0.15)(Wk(°)2
i1
Q
在进行序贯重要性采样时,若Neff小于事先设定的某一阈值,则应当采取一些措施加以控制。
克服序贯重要性采样算法权值退化现象最直接的方法是增加粒子数,而这会造成计算量的相应增加,影响计算的实时性。
因此,一般采用以下两种途径:
("选择合适的重要
性概率密度函数;
(2)在序贯重要性采样之后,采用重采样方法。
重要密度函数的选择
重要性概率密度函数的选择对粒子滤波的性能有很大影响,在设计与实现粒子滤波器的过程中十分重要。
在工程应用中,通常选取状态变量的转移概率密度函数P(XkIXkJ作为重要性概率密度函数。
此时,粒子的权值为wk:
i)Wk-1p(yk|xk:
)(0.16)转移概率的形式简单且易于实现,在观测精度不高的场合,将其作为重要性概率密度函数可以取得较好的滤波效果。
然而,采用转移概率密度函数作为重要性概率密度函数没有考虑最新观测数据所提供的信息,从中抽取的样本与真实后验分布产生的样本存在一定的偏差,特别是当观测模型具有较高的精度或预测先验与似然函数之间重叠部分较少时,这种偏差尤为明显。
选择重要性概率密度函数的一个标准是使得粒子权值M的方差最小。
Doucet等给
出的最优重要性概率密度函数为
q(xkw
p(yk
Xk0)i,Yk)pfxkjxk-iyk)
P(yk|xk;,XkhjpCxkJxk^)
p(ykIxfj
此时,粒子的权值为
Wk⑴Wk「p(ykIxvi)(o.18)
以P(xk-|XkSyj作为重要性概率密度函数需要对其直接采样。
此外,只有在Xk为有
限离散状态或p(xk>|Xkh,yk)为高斯函数时,p(ykIxjJ才存在解析解。
在实际情况中,构造最优重要性概率密度函数的困难程度与直接从后验概率分布中抽取样本的困难程度等同。
从最优重要性概率密度函数的表达形式来看,产生下一个预测粒子依赖于已有的粒子和最新的观测数据,这对于设计重要性概率密度函数具有重要的指导作用,即应该有效利用最新的观测信息,在易于采样实现的基础上,将更多的粒子移动到似然函数值较高的区域,如图2.4所示。
图2.3移动粒子至高似然区域
Fig.2.3MovethesampIesinthepriortoregionsofhighIikeIihood
辅助粒子滤波算法利用k时刻的信息,将k1时刻最有前途(预测似然度大)的粒子扩展到k时刻网,从而生成采样粒子。
与sir滤波器相比,当粒子的似然函数位于先验分布的尾部或似然函数形状比较狭窄时,辅助粒子滤波能够得到更精确的估计结果。
辅助粒子滤波引入辅助变量m来表示k1时刻的粒子列表,应用贝叶斯定理,联合概率密度函数p(xk,m|yi:
k)可以描述为
p(xk,m|yi:
k)p(yk|Xk)p(xk,mIyi:
k1)
p(yk|Xk)p(xt|m,yi:
k1)p(m|yi:
k1)p(yk|Xk*)p(xk|Xk^i)Wk'i(0.19)
生成{x-,mJ:
的重要性概率密度函数4(xk,m|x0:
k1,yi:
k)为
q(xk,m|xo:
k1,yi:
k)p(yk|kjp(xk|Xk-1)Wk-i(0.20)
其中k“为由{Xk-l}iM预测出的与Xk相关的特征,
可以是采样值“P(Xk|XkM)或预
测均值k・E{xk|1}o
^q(xk|m,yi:
k)p(xk|xrm),由于
q(xk,m|yi:
k)
则有
q(m|yi:
k)p(yk
w(i)泗⑺p(yk|
WkWk(
q(
采用局部线性化的方法来逼近p(xk|xk1,yk
法。
扩展Kalman粒子滤波与Uncented粒子滤波算法在滤波的每一步迭代过程中,首先利用最新观测值,采用UKF或者EKF对各个粒子进行更新,得到随机变量经非线性变换后的均值和方差,并将它作为重要性概率密度函数丽。
另外,利用似然函数的梯度信息,采用牛顿迭代冋或均值漂移何等方法移动粒子至高似然区域,也是一种可行的方案,如图2.5所示。
以上这
些方法的共同特点是将最新的观测数据融入到系统状态的转移过程中,引导粒子到高似然区域,由此产生的预测粒子可较好地服从状态的后验概率分布,从而有效地减少描述后验概率密度函数所需的粒子数。
q(xk|m,yi:
k)q(m|yi:
k)(0.21)
Ik)Wk竹(0.22)止匕时,粒子权值Wk⑴为
Xk
))p(xk|xk")p(yk|Xk:
i)(0.23)
fm(i|)(0、23)xo-k1,yk)p(yk|Q
)是另一种提高粒子采样效率的有效方
x”,N
}{xk>,N
}
{x;>,w?
}
{xk%Wk4
图2.4结合均值漂移的粒子滤波算法
Fig・2.4ParticIefiltercombinedwithmeanshift
重采样方法
针对序贯重要性采样算法存在的权值退化现象,Gordon等提出了一种名为Bootstrap的
粒子滤波算法。
该算法在每步迭代过程中,根据粒子权值对离散粒子进行重采样,在一定程度上克服了这个问题。
重采样方法舍弃权值较小的粒子,代之以权值较大的粒子。
重采样过程在满足p(xk*>xk-)Wk⑴条件下,将粒子集合{XL,Wk“}r更新为{x(k-,1/N}fo
重采样策略包括固定时间间隔重采样与根据粒子权值进行的动态重采样。
动态重采样通常根据当前的有效粒子数或最大与最小权值比来判断是否需要进行重采样。
常用的重采样方法包括
多项式(Multinomialresampling)重采样、残差重采样(Residualresampling)、分层重采样
(Stratifiedresampling)与系统重采样(Systematicresampling)等。
残余重采样法具有效率
高、实现方便的特点。
设N,NWk⑴,其中为取整操作。
残余重采样采用新的权值
Wk*11Nk'NwkG,N1卅你淋nn'个粒子,如图2.6所示。
残余重采样i1
的主要过程为
(D计算剩余粒子的权值累计量j,j1,,Nko
(2)生成Nk在个[0,1]区间均匀分布的随机数{■}rki;
(3)对于每个*,寻找归一化权值累计量大于或等于•的最小标号m,即
ml'mo当藩在区间[mbm]时,Xf被复制一次。
这样,每个粒子XL经重采样后的个数为步骤(3)中被选择的若干粒子数目与N之和。
图2.5残差重采样
Fig・2.5ResiduaIResampIing
重采样并没有从根本上解决权值退化问题。
重采样后的粒子之间不再是统计独立关系,给估计结果带来额外的方差。
重采样破坏了序贯重要性采样算法的并行性,不利于VLSI硬件实现。
另外,频繁的重采样会降低对测量数据中野值的鲁棒性。
由于重采样后的粒子集中包含了多个重复的粒子,重采样过程可能导致粒子多样性的丧失,此类问题在噪声较小的环境下更加严重。
因此,一个好的重采样算法应该在增加粒子多样性和减少权值较小的粒子数目之间进行有效折衷。
图2.7为粒子滤波算法的示意图,该图描述了粒子滤波算法包含的时间更新、观测更新和重采样三个步骤。
k1时刻的先验概率由N个权值为1/N的粒子Xkh近似表示。
在时间更新过程中,通过系统状态转移方程预测每个粒子在k时刻的状态Xf经过观测值后,更新粒子权值WF。
重采样过程舍弃权值较小的粒子,代之以权值较大的粒子,粒子的权值被重新设置为1/No
{昭冋
图2.6SIR算法示意图
Fig.2.6SIRalgorithm
标准的粒子滤波算法流程为:
(1)粒子集初始化,k0:
对于i1,2,,N,由先验p(xo)生成采样粒子{xo}iKi
(2)对于k1,2,,循环执行以下步骤:
①重要性采样:
对于i1,2,,N,从重要性概率密度中生成采样粒子{xk}h,计算粒子权值wj,并进行归一化;
②重采样:
对粒子集{xv,wkJ进行重采样,重采样后的粒子集为{Xk-,1/N};
N
③输出:
计算k时刻的状态估计值:
x?
kxkf,Wk°o
i1
粒子滤波中的权值退化问题是不可避免的。
虽然重采样方法可以在一定程度上缓解权值退化现象,但重采样方法也会带来一些其它的问题。
重采样需要综合所有的粒子才能实现,限制了粒子滤波的并行计算。
另外,根据重采样的原则,粒子权值较大的粒子必然会更多的被选中复制,经过若干步迭代后,必然导致相同的粒子越来越多,粒子将缺乏多样性,可能出现粒子退化现象,从而使状态估计产生较大偏差。
针对粒子退化问题,一个有效的解决方法是增加马尔可夫蒙特卡洛(Markovchainmontecarlo,MCMC)移动步骤t,4,]。
马尔可夫链蒙特卡洛方法(女口Gibbs采样、Metropolis-Hastings采样等)利用不可约马尔可夫过程可逆平稳分布的性质,将马尔可夫过程的平稳分布视为目标分布,通过构造马尔可夫链产生来自目标分布的粒子。
粒子退化问题是由于重采样使得粒子过分集中在某些状态上而导致的,对重采样后的粒子进行马尔可夫跳转可以提高粒子群的多样性,同时保证跳转后的粒子同样能够准确的描述既定的后验分布。
设粒子分布服从后验概率P(X0:
k|yi:
k),实施核为k(Xo:
k|x°:
k)的马尔科夫链变换之后,若满足
k(xo:
k|xo:
k)p(xo:
k|yi:
k)dxo:
kp(xo:
k|yi:
k)(0.24)
便可以得到一组满足既定后验概率分布的粒子集合,且这组新的粒子可能移动到状态空间
中更为有利的位置。
采用Metropolis-Hastings算法,从概率密度q(X)中生成粒子的具体步骤为:
(1)从
[0,1]之间的均匀分布中生成随机数VU[0,1];
(2)从重要性概率密度函数中生成采样粒子Xk-p(x・kIXk);
⑶如果vminqq((xX(k,ki)))Pp((xxk(k*')ilxXkCki))),接受xk-,否则,拒绝Xk・
1,
另一种解决粒子退化问题的方法是正则


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 粒子 滤波 matlab 实现
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《贝的故事》教案4.docx
《贝的故事》教案4.docx
-
《对韵歌》优秀教案8.docx
-
《函数yAsinωx+φ+P图象》wwwnet.docx
-
《静夜思》教学设计.docx
-
《汽车底盘构造与维修》题库与考核标准.docx
-
《世说新语》复习资料.docx
-
《我的服装我做主》教案设计.docx
-
《在品味情感中成长》教学片断设计.docx
-
11造价员《建设工程造价管理基础知识》精讲教程文件.docx
-
《不会叫的狗》教案 人教部编版1.docx
-
《操作系统》二学期A卷及答案.docx
-
《傅雷家书》名著阅读笔记.docx
-
《反不正当竞争法》下互联网平台封禁行为考辨以消费者用户合法权益保护为中心.docx
-
《化工原理》第六章蒸发.docx
-
《蓝海战略》概要11页.docx
-
《人生》读书心得.docx
-
《荷叶圆圆》公开课教案优秀教学设计26.docx
-
《科技出行研究报告》智能网联与新能源将变革未来汽车出行.docx
-
《272 向量的应用举例》导学案1.docx
-
《秋天》评课稿.docx
-
《电算化》第二章会计电算化的工作环境章节练习.docx
-
《室外给排水管道》施组.docx
-
《广东省建筑与装饰工程综合定额》计算规则.docx
-
《我多想去看看》教学.docx
-
《直通车车手基础认证》 考试答案 70题之欧阳育创编.docx
-
7天销量翻10倍皇冠卖家教您玩转最精准流量.docx
-
9 阿长和山海经.docx
-
《比例尺》教案.docx
-
《菜根谭》注译四闲适篇.docx
-
《福尔摩斯探案集》读后感15篇.docx
-
《红对勾》古代诗歌选择题答案补充.docx
-
《课堂密码》读后感及心得精选多篇.docx
-
体育武术初级拳教案文档格式.docx
-
恩施特色小吃与旅游发展Word文件下载.docx
-
蟋蟀的住宅短文阅读附答案Word文档格式.docx
-
钢结构习题Word格式.docx
-
学前教育毕业论文中秋文档格式.docx
-
学校教师管理规章制度大全文档格式.docx
-
物业管理工程的编制依据文档格式.docx
-
室内空气质量检测报告四篇Word格式.docx
-
实用的雇佣合同集合五篇文档格式.docx
-
五年级单位换算Word文件下载.docx
-
高考语文题型归纳文档格式.docx
-
小学班主任上学期工作总结Word文件下载.docx
-
乡村生态旅游项目策划Word文件下载.docx
-
经典格言中英文对照中英文对译的教育格言Word文档格式.docx
-
关于资料员实习日记合集8篇文档格式.docx
-
规范版专业行业调研报告2篇Word文档格式.docx
-
河道工程护砌连锁砌块施工及方案Word文档下载推荐.docx
-
服装QC检验标准和成品基本品质要求Word文档格式.docx
-
河南科技大学本专科学年学分制学生学籍管理细则Word格式.docx
